Vom gedruckten Buch zur digitalen Karte
Vorwort
DHVLab-Ausbildungsvorhaben "Erstellung einer interaktiven Karte" im Rahmen des Vertiefungskurses "Begräbniskultur in der Frühen Neuzeit" (Prof. Dr. Mark Hengerer), Wintersemester 2016/2017
Folgende DHVLab-Komponenten werden verwendet:
- Virtueller Desktop
- Calc (Start → Anwendungen → Bürosoftware)
- Dia (Start → Anwendungen → Grafik)
- KATE Texteditor (Start → Anwendungen → Dienstprogramme)
- MySQL-Datenbank (dhvlab.gwi.uni-muenchen.de/sql bzw. über den virt. Desktop: web.dmz.dhvlab.fo/sql)
- Cloud (Import/Export von Dateien aus oder in die Umgebung)
- Handbücher: Einführung in die Tabellenkalkulation (Calc) und Einführung in die Arbeit mit Datenbanken
Datengrundlage:
Brigitta LAURO, Die Grabstätten der Habsburger. Kunstdenkmäler einer
europäischen Dynastie. Wien 2007
→ Personenregister samt Begräbnisstätten (25 Seiten à durchschnittlich
22 Personeneinträge = ca. 550 Einträge1)
Ziel:
- Grundlegendes Verständnis für die strukturierte Aufnahme von Forschungsdaten mit einem Tabellenkalkulationsprogramm zur anschließenden Datenhaltung, -modellierung und -manipulation in einer relationalen Datenbank
- Anreicherung der Daten um zusätzliche Meta- und Normdaten
- Kennenlernen der Datenbankumgebung phpMyAdmin
- Erlernen der Datenbanksprache SQL zur effizienten Arbeit mit den erarbeiteten Forschungsdaten
- Grundzüge von HTML/CSS/JavaScript zur Erstellung dynamischer Karten unter Einbindung der zuvor generierten Forschungsdaten (mit Hilfe der Google Maps API). Hierfür eignen sich Grabdenkmäler aufgrund ihrer Georeferenzierbarkeit in besonderer Weise
- Anschließende Veröffentlichung als interaktive Karte ("Forschung aus Lehre")
→ Sie erlernen Grundlagen der Datenaufnahme und -verarbeitung samt
anschließender Visualisierung und damit grundlegende technische
Kompetenzen für die Anwendung auf Ihre geisteswissenschaftliche
Fragestellungen.
Die Kursleiter setzten gemeinsam mit einigen Teilnehmern das Projekt
nach Semesterende fort. Die aktuelle Version der Karte ist auf folgender
Seite abrufbar:
http://www.habsburg.gwi.uni-muenchen.de/2
Anmerkungen
- Hinzu kommen noch weitere Einträge, da auch die Eltern der Personen aufgenommen wurden, die in vielen Fällen - aber eben nicht immer - selbst als Personen in der Liste angeführt werden.↩︎
- Vgl. auch "DH Project in Process".↩︎
Einführung
Bedeutung von IT-Grundkenntnissen für Geisteswissenschaftler/-innen:
- Arbeitsmarktentwicklung der vergangenen Jahre: Auch von Geisteswissenschaftlern wird verstärkt ein grundlegendes Verständnis für informationstechnologische Methoden und die Anwendung von Software erwartet (Stichwort "Digital Humanities"). Dadurch eröffnen sich für Absolventen einerseits neue Möglichkeiten auf dem außeruniversitären Arbeitsmarkt; andererseits suchen zunehmend "klassische" Arbeitgeber (ob Universität, Forschungseinrichtungen, Verlage, Museen, Archive oder Bibliotheken) Absolventen, die ein gewisses Maß an digitaler Kompetenz vorweisen können. Der Bedarf an digital versierten Geisteswissenschaftlern ist sehr groß - und er wird weiter steigen.
- Neben der Verbesserung der beruflichen Perspektive gibt es noch einen zweiten, wichtigen Aspekt, auf den an dieser Stelle verwiesen sei: Wenn Historiker die Deutungshoheit über die Geschichte behalten möchten, müssen sie sich mit ihrer visuellen Darstellung im digitalen Medium auseinandersetzen. Sonst werden es andere Akteure sein, die ihre Sicht der Welt als "historische Wahrheit" verkaufen, und die kritische Geschichtsforschung hinter sich lassen.
An dieser Stelle seien ein paar, zufällig
ausgewählte Jobangebote des einschlägigen Portals
HSozKult angeführt:
- "sehr gute IT-Kenntnisse"
wiss. Volontariat am Heinrich-Heine-Institut Düsseldorf im Bereich Archiv-Bibliothek-Museum - "Der sichere Umgang mit digitalen Medien [...] werden
erwartet."
Promotionsstelle "Didaktik der Geschichte"> - "[...] nachgewiesene Grundkenntnisse und praktische Erfahrungen im
Bereich der Digital Humanities, insbesondere im Umgang mit
Datenbanksystemen und Content Management Systemen"
Wiss. Volontariat am Institut für Geschichtliche Landeskunde, Uni Mainz - "sicherer Umgang mit gängigen Web- und
Datenbanktechnologien"
Wiss. Mitarb. "Digitale Lehre und Forschung", Univ. Zürich
⇒ Das Projekt "IT for
All" im Rahmen der Förderlinie "Digitaler Campus Bayern"
setzt hier an (vgl. Projektbeschreibung).
Im Rahmen des Projekts entsteht das DHVLab1,
eine interaktive Lehr- und Lernumgebung, die im Rahmen
dieses Kurses zum Einsatz kommt.
Aufgaben:
- Registrieren Sie sich für das DHVLab unter Auswahl des entsprechenden Labs (Grabdenkmaeler)2. Lesen Sie sich das Handbuch 3 durch, damit sie alle Komponenten der Umgebung gewinnbringend verwenden können. Machen Sie sich mit dem Virtuellen Desktop, dem Herzstück der Plattform, vertraut.
- Überlegen Sie sich, welche Features die gemeinsam zu erstellende Karte aufweisen soll und welche inhaltlichen Informationen aus Ihrer Sicht aufgenommen werden sollten.
Hinweise zur Benutzung:
- Wir empfehlen für den virt. Desktop die Verwendung des Web-Browsers Google Chrome (andere Browser funktionieren i.d.R. auch)
- Beim allerersten Start des virt. Desktops erhalten Sie eine Fehlermeldung → Fenster schließen und nochmals neu öffnen - jetzt funktioniert es.
- Login erfolgt über das "Virtueller Desktop" im Bereich "Module", nicht jedoch über das Feld "Login" oben rechts am Seitenrand (interner Login für die Projektmitarbeiter).
- Für alle Komponenten des DHVLab verwenden Sie stets die gleichen Anmeldedaten.
- Speichern Sie Ihre Dateien stets in der Cloud des DHVLab ab (zu finden auf der Startseite im Footer unter "Sonstiges"); dadurch können Sie sie bequem auf Ihren Home-Desktop kopieren und umgekehrt. Im Handbuch zur Einführung in die Benutzung wird beschrieben, wie Sie Ihre Cloud in wenigen Schritten aktivieren.
- Anzeigeeinstellungen im virt. Desktop anpassen: Um die Auflösung des virtuellen Desktops an Ihr Endgerät optimal anzupassen, befolgen Sie bitte die Hinweise in unserem Video.
- Für Kursleiter: Rechtevergabe für den jeweiligen Kursordner auf dem virt. Desktop: Rechtsklick → Eigenschaften → Berechtigungen → Erweiterte Berechtigungen → Auswahl treffen Ξ phpMyAdmin: Rechtevergabe für Kursdatenbank bzw. einzelne Tabellen erfolgt durch anwählen der jeweiligen Datenbank/Tabelle → Mehr → Rechte → Auswahl treffen.
Anmerkungen
Karten als Medium der Visualisierung historischer Daten
Karten eignen sich in besonderer Weise dazu, komplizierte Sachverhalte anschaulich darzustellen1. Wenngleich eine Karte zunächst einmal eine zweidimensionale Darstellung eines dreidimensionalen Raumes ist - was notwendigerweise eine gewisse Reduktion mit sich führt - stellt sie für die historische Forschung eine komplementäre Ebene dar, die Historikern die Möglichkeit bietet, Wissenssammlungen ansprechend zu visualisieren2. Diese geographische Dimension rückt in den vergangenen Jahren durch die digitalen Möglichkeiten verstärkt in den Fokus der Wissenschaft3, die sich bis dato den Vorwurf gefallen lassen musste, die "spatial dimension" zu vernachlässigen4.
Grundlegendes zu Karten
- Vektorgraphenmodell: Grundlage jeder georeferenzierter Darstellung ist das geographische Koordinatensystem, auch Vektorgraphenmodell genannt. Bei den Koordinaten handelt es sich um eine Kombination aus Längen- (0-180°, in Richtung West und Ost) und Breitengraden (0-90°, in Richtung Nord und Süd). Ihr Schnittpunkt ergibt jeweils einen Punkt auf der Karte, der jegliche Form von Information beinhalten kann.
- Linien: Zwei oder mehrere miteinander verbundene Punkte ergeben eine Linie. Während bei Linien der Breitenwert keine Aussage besitzt, ist der Abstand zwischen zwei Punkten für die Länge der Linie entscheidend. Flüsse, Grenzen oder Straßen sind beispiele für Linien.
- Polygone: Eine Gruppe von verbundenen Linien stellen ein Polygon dar, welches einen Bereich umfasst und damit eine geographische Fläche, z.B. ein Territorium, definiert.
- Folgende Informationen sind Grundbestandteil einer jeden
Karte:
- Kartentitel
- Legende (welche Symbole finden in der Karte Anwendung)
- Einnordung der Karte (durch einen Pfeil oder eine Kompassrose)
- Maßstabsangabe (z.B. 1:250 000 = "Ein Zentimeter in der Karte entspricht 250 000 Zentimetern in der der Wirklichkeit")
- Beschriftungen (z.B. bei Flüssen, Städten, Straßen)
- "Layer": Die vorgenannten Informationen sind in einer vorgefertigten, um geographische Informationen angereicherten Karte (z.B. Google Maps, Open Street Map) bereits vorhanden. Man spricht hier von einem sogenannten "Layer".
- Es ist möglich, alte Karten(ausschnitte) in GIS-Systeme einzubinden. Wichtig ist die anschließende Georeferenzierung (= Verknüpfung mit Koordinaten) markanter Punkte, um die geographischen Angaben der alten Kartenansicht mit denen des Layers in Übereinstimmung zu bringen.
- Es gibt mittlerweile eine wachsende Zahl an
Portalen für alte Kartenansichten, z.B.:
- Old Maps Online
- Mapire - Historische Karten der Habsburger Monarchie
- Virtuelles Kartenforum 2.0
Beispiele für in Karten visualisierte Datensammlungen
Dass die kartographische Visualisierung (historischer) Informationen immer beliebter wird - und es somit sinnvoll erscheint, den Weg dorthin zu erlernen - soll anhand einiger ausgewählter Beispiele gezeigt werden:
- Kaiserhof-Projekt (Prof. Dr. Mark Sven Hengerer und Dr. Gerhard Schön)
- Deutsche Biographie, jüngst ebenfalls erweitert um eine kartographische Komponente
- Projekt "40 Jahre - 40 Projekte" der Gerda-Henkel-Stiftung
- Repertorium Academicum Germanicum
- weitere Mapping-Projekte
→ all diese Projekte basieren auf strukturierten Datensammlungen5. Manche von Ihnen verwenden zur Darstellung die Google Maps API, andere das Pendant Open Street Map.
Entscheidung für die Verwendung von Google Maps
- Es gibt eine schier unüberschaubare Zahl an
GIS-Software (GIS = Geo
Informations System) auf dem Markt
- Manche davon sind sehr leistungsstark, jedoch auch entsprechend kostspielig
- Manche sind zwar kostenlos, jedoch auch im Umfang ihrer Möglichkeiten eingeschränkt (z.B. Dariah GeoBrowser)
- Allgemein gilt: Man sollte sich möglichst nicht von (non-)proprietärer Software abhängig machen, sondern sich das notwendige Know-How aneignen, mit dem die Erstellung unabhängig von der verwendeten Software erfolgen kann → daher fällt die Wahl auf die Google Maps API, da hier mit HTML/JavaScript ein qualitatives und funktional umfassendes Ergebnis erzielt werden kann.
- Auch der Einsatz von Open Street Map (OSM) als Alternative zur Google Maps-API wäre denkbar, jedoch hält OSM beispielsweise nicht die Möglichkeit bereit, in den Street View-Modus zu gelangen. Letzteres erscheint vor dem Hintergrund der Visualisierung von Grabstätten jedoch erstrebenswert.
Diskussion der Datengrundlage

Ergebnisse der Diskussion mit den Kursteilnehmern:
- Gedruckte Version:
- Anordnung erfolgt alphabetisch, geordnet nach Namen des jeweiligen Habsburgers
- Namensformen unterscheiden sich jedoch zuweilen (z. B. taucht die Bezeichnung "Ernst" und "Ernst der Eiserne" für dieselbe Person auf)
- Statisch, d.h. keine Möglichkeit, die Personen nach anderen Kriterien anzuordnen (z. B. Bestattungsort, Sterbejahr, Rang etc.)
- Fehlende Durchsuchbarkeit
- Zusammenhänge zwischen einzelnen Personen können nicht dargestellt werden
- Strukturierte Anordnung in Tabellenform, die jedoch keinen Spielraum für eine visuelle Darstellung bietet (z. B. Einbindung von Abbildungen, weiterführenden Informationen)
- Geplante digitale Visualisierung als Karte:
- Anordnung dynamisch, je nach Auswahlkriterium des Benutzers
- Interaktiv, d.h. es besteht die Möglichkeit, selbst zu bestimmen, welche Datensätze und welche zugehörigen Informationen angezeigt werden sollen ("zeige alle Personen, die in XY begraben sind", "Zeige nur Personen, die im 18. Jahrhundert gelebt haben")
- Zusammenhänge zwischen einzelnen Personen können dargestellt werden ("zeige die Grabstätten der Nachfahren von Person XY")
- Anzeige von Netzwerken (z.B. Verwandschaftsbeziehungen)
- Visuell ansprechende Gestaltung in Form einer Karte u.a. mit der Möglichkeit, an die ermittelte Begräbnisstätte via Google Street View heranzuzoomen.
- Mehrwert an Information durch Einbindung in die digitale Wissenschaftsinfrastruktur (d.h. Anreicherung mit Metainformationen wie Ortsinformationen, Kaiserhof-Projekt-ID, Normdaten wie GND, VIAF und NDB, Wikidata, Wikipedia-Einträge etc.)
- Einbindung von Abbildungen der Grabdenkmäler und/oder der Personen
Fazit: Es handelt sich um eine reichhaltige Datenquelle, die durch die Begrenzungen des Mediums 'gedrucktes Buch' jedoch nicht in der Intensität ausgeschöpft werden kann, wie es für den Historiker wünschenswert wäre. Die strukturierte Aufnahme der Forschungsdaten, ihre Anreicherung um Metadaten und zusätzlichen Informationen sowie die Vernetzung mit bestehenden Online-Angeboten verspricht eine erhebliche Steigerung des Mehrwerts der Datensammlung. Neben dem Zugewinn an Interaktivität, Benutzerfreundlichkeit und visuell ansprechender Gestaltung können aus den genannten innovativen Features nicht zuletzt neue wissenschaftliche Fragestellungen erwachsen.
Anmerkungen
- Vgl. A GIS (Handbuch) , S. 6: "Understanding the geographical space in which human history occured is an important part of understanding that history, and GIS allows historians to fill in that gap."↩︎
- Eine gute Einführung in das Themenfeld Georeferenzierung bietet: Linda L. Hill, Georeferencing: The Geographic Associations of Information. Cambridge u.a. 2006 (Paper 2009).↩︎
- Vgl. bspw. die Tagung "Creating Spatial Historical Knowledge" am Deutschen Historischen Institut Washington, Oktober 2016, oder auch den dhmuc-Workshop an der BAdW München im Juli 2017.↩︎
- Vgl. A GIS (Handbuch), S. 6: "Human history necessarily includes a spatial dimension, which historians often overlook."↩︎
- Vgl. A GIS (Handbuch), S. 7: "A GIS is a specialised form of a database because each item of data...is linked to a coordinate-based representation of the location that the data refers to. Thus, GIS combines spatial data in the form of points, lines, polygons, or grid cells, with the attribute data held in conventional database form."↩︎
Datenaufnahme mit Calc
Unser Kursziel ist es, in gedruckter Form vorliegende Daten in strukturierter Form zu erfassen und für die spätere Weiterverarbeitung in eine Datenbank einzupflegen. Eine Möglichkeit wäre es, die entsprechenden Buchseiten mit einem OCR-Programm zu erfassen und die damit gewonnenen Daten im Anschluss aufzubereiten. Die Einführung in die Benutzung einer OCR-Software war jedoch im Rahmen dieses Kurses nicht möglich, daher wurden die Daten händisch mit einem Tabellenkalkulationsprogramm erfasst. Ob händisch oder maschinell - die Aufgabe der anschließenden Datenstrukturierung bleibt unverändert.
Forschungsdaten
"Alle Arten von Information können auf Tabellen heruntergebrochen werden"
Bevor wir uns der Datenaufnahme zuwenden, seien an dieser Stelle ein
paar grundlegende Gedanken zu unserem Gegenstand, den Forschungsdaten,
angeführt.
Forschungsdaten
- sind all diejenigen Daten, die im Laufe eines Forschungsprozesses anfallen und für die Begründung eines Forschungsergebnisses notwendig sind.
- stellen den Ausgangspunkt jeder wissenschaftlichen Arbeit dar
- sollten in einem sinnvollen Datenformat gehalten werden, damit eine softwareunabhängige Weiterverarbeitung möglich ist (z. B. CSV)
- werden in der Regel mit einem Tabellenkalkulationsprogramm wie Excel/Calc strukturiert erfasst; die Datenerfassung ist auch unmittelbar über eine Datenbank möglich, jedoch bietet Calc hierfür eine intuitive, graphische Benutzeroberfläche, weshalb sich das Programm anbietet
- sollten von Beginn an nach ausgewählten, nachvollziehbaren Kriterien strukturiert werden, um eine spätere, mit größerem Arbeitsaufwand verbundene Überarbeitung zu vermeiden1
Naiver Umgang mit Forschungsdaten: Leider finden sich gerade in den Geisteswissenschaften bis heute zahlreiche Beispiele für einen 'naiven' Umgang mit Daten, d.h. ein werkzeugzentriertes Arbeiten überwiegt ein datenorientiertes Denken. Beispielsweise werden Bibliographien in Hausarbeiten zumeist in einer Word-Datei in Textform gesammelt, seltener in einem hierfür geeigneten Literaturverwaltungsprogramm wie Zotero oder Citavi. Dies bringt folgende negative Begleiterscheinungen mit sich:
- mangelnde Nachnutzbarkeit der Daten, da nicht auf die Datenstruktur zugeschnitten
- maschinelle Weiterverarbeitung der Daten erschwert oder unmöglich
- erschwerte Einbindung in bestehende digitale Infrastrukturen (Datenrepositorien)
- geringe Transparenz der Forschung
Datenaufnahme mit Calc
→ Für weiterführende Informationen sei auf die Einführung in die Datenaufnahme mit Calc verwiesen.
"Wer Calc kann, kann auch Excel" Die Datenaufnahme erfolgt mit i.d.R. mit einem Tabellenkalkulationsprogramm wie Calc oder Excel. Calc, die kostenlose Alternative zu Excel, steht seinem kostenpflichtigen Pendant in der Funktionalität ebenbürtig gegenüber. Es findet im DHVLab Anwendung, da sich das Projekt für den Einsatz non-proprietärer Software ausspricht (Stichwort: Unabhängigkeit bestimmter Herstellerformate). → Öffnen Sie Calc im Virtuellen Desktop wie folgt: Startbutton -> Anwendungen -> Büroprogramme → In Calc können Dateien als ods- (Open Document Spreadsheet) oder xls-Format abgespeichert werden; das Öffnen mit Excel (und umgekehrt) ist problemlos möglich. → Für den späteren Import der Daten in die Datenbank bietet sich die Verwendung des Formats CSV (Comma Separated Values) an. Wichtig: Für den Import kann immer nur EINE Tabelle einbezogen werden, d.h. es muss für jede Tabelle eine neue CSV-Datei angelegt werden!
Bereits vor der Datenaufnahme in Calc/Excel ist es unabdingbar, dass man sich Gedanken zum Datenschema macht. Wie soll die spätere Datenbank strukturiert sein? Welche Erkenntnisinteressen verfolge ich mit den aufzunehmenden Forschungsdaten? (= reflektiertes Arbeiten)
- Der wichtigste Grundsatz bei der Strukturierung von Forschungsdaten lautet: Exaktes Arbeiten!
- Nur, wenn Daten sauber strukturiert abgelegt werden, können sie später maschinell verarbeitet werden.
- Thesen können messbar gemacht werden (= Operationalisieren) → Unterschiedliche Fragestellungen führen zu unterschiedlichen Datenmodellen: Auswahl treffen - Untersuchungsform wählen
- Die Datenaufnahme und -strukturierung nimmt etwa 80% der Zeit ein! Organisation ist alles in einem Datenbank-Projekt.
Die erarbeitete Liste der Begräbnisstätten der Habsburger stellt eine große Bereicherung für die wissenschaftliche Beschäftigung mit der Geschichte der habsburgischen Dynastie dar. Diese wissenschaftliche Leistung soll in keiner Weise in Abrede gestellt werden. Über die, dem Medium "gedrucktes Buch" geschuldeten Nachteile der Auflistung wurde bereits weiter oben mit den Teilnehmern diskutiert. Hinzu kommen kleinere inhaltliche Inkonsistenzen bzw. Unsicherheiten, bei deren Erfassung in Form einer Datenbank sich die Frage nach der Strukturierung im Besonderen stellt. Die Diskussion mit den Teilnehmern führte u.a. zu folgenden Beobachtungen:
- Wie modelliert man Unsicherheiten? (z. B. circa-Angaben, "um ...", "(?)"; z.B. "Rudolf, ?-vor 1424", "Richenza, um 1050")
- Welche Angaben werden bei mehreren Möglichkeiten verwendet? (z.B. "Sticna (Sittich)")
- Uneinheitliche Angaben erschweren eine quantitative Analyse (z.B. "Kloster Muri/Aargau" vs. "Kloster Muri/Schweiz"; "Basilika Ste.-Denis/bei Paris" vs. Ste.Denise/Paris")
- Selbiges gilt für unvollständige Angaben (z.B. "Porto Alegre" - ohne Angabe der Grabstätte oder deren Ungewissheit)
- Wie verfährt man mit der Tatsache, dass mehrere Personen in derselben Grabstätte liegen?
- Wie verfährt man mit der Tatsache, dass Personen an mehreren Orten begraben liegen? (Herz, Eingeweide, Körper, z. B. "Kapuzinergruft/Wien", Int.-U.: Herzogsgruft St. Stephan/Wien, H.-U.: Krypta im Dom/Olmütz")
→ Für uns Geisteswissenschaftler birgt dieses strukturierte Arbeiten
mit Daten viele Vorteile, u.a. dass man sich mit allen Problemfällen
auseinandersetzen muss und verbindliche Kriterien mit einhergehender
Entscheidungsfindung geschaffen werden müssen.
→ Dabei gilt
stets: Auswahlkriterien gut dokumentieren. Inhaltliche Entscheidungen
müssen als solche erkennbar sein. Ihre Dokumentation ist wichtig, da das
Wissen darüber ansonsten (z. B. bei einem Personalwechsel) schnell
verloren gehen kann.
→ Neben der Dokumentation der
Datenstruktur muss auch die einbezogene Datenbasis genau beschrieben
werden, um signifikante und vertrauensvolle Werte anbieten zu können.
(z. B.: "Von den in der Datenbank erfassten Personen werden nur 80%
ausgegeben, da bei den anderen 20% keine Geodaten ermittelt werden
konnten.")
Übungsaufgabe
Ein kleines Übungsbeispiel zum Einstieg:
- gegeben ist folgende Calc-Datei, in der sich einige
Personendatensätze2 befinden:
(// Übungsdatei einbinden) - Machen Sie sich Gedanken darüber, welche Informationen aus Ihrer Sicht besser strukturiert werden sollten und bringen Sie die Datei in eine saubere Form.
Lösungsvorschläge
- Entfernen Sie gestalterische Elemente, wie die Hervorherbung der Überschriftzeile
- Vereinheitlichen Sie die Überschriftenzeile: Es wird durchgängige Kleinschreibung empfohlen wie auch die Verwendung von talking names (GB → geburtsdatum), Leerzeichen sollten vermieden werden (Name der Person → personenname), ebenso Umlaute (Begräbnisstätte → begraebnisstaette)
- Personenname: Vereinheitlichung der Angabe römisch-deutsch → röm.-dt.
- Geschlecht: Kürzel "m" und "w" sinnvoll, jedoch einheitlich (ein Fall mit "weiblich" → "w")
- Unsicherheiten beim Sterbedatum: für die mit (?) gekennzeichnete Unsicherheit bietet es sich an, eine eigene Spalte zu erstellen, in der das Merkmal Unsicherheit abgefragt wird (1 = ja, 0 = nein). Eine weitere Spalte erscheint sinnvoll für unsichere Fälle, in denen es eine alternative Angabe gibt (1603, 1604)
- Begräbnisstätte: Hier gibt es gleich mehrere kleinere Ungenauigkeiten zu beheben: In einem Fall ist auch das Land mit angegeben; diese Angabe sollte in einer eigenen Spalte eingegeben werden, muss dann aber auch für alle anderen Orte nachgetragen werden. Vereinheitlicht werden muss auch die Ortsangabe: Komma anstelle Semikolon, Komma anstelle Klammern, Wien ergänzen bei Kapuzinergruft.
- Geokoordinaten: Angabe "(siehe oben)" ersetzen durch die entsprechenden Koordinaten
- Nach diesen ersten Aufräumarbeiten gilt es nun, die Informationen
einiger Spalten noch zu trennen. So erscheint es sinnvoll, die Rolle der
Personen in einer eigenen Spalte getrennt vom Namen zu sammeln, ebenso
den Ortsnamen von der Grabstätte zu trennen und auch die Geokoordinaten
auf zwei Felder aufzuspalten. Dadurch werden die Informationen flexibel
einsetzbar und für quantifizierende Auswertungen brauchbar. Hierfür gibt
es zwei Möglichkeiten:
- 1. Einsatz einer Funktion: Wir fügen zunächst zwei leere Spalten
rechts neben der Spalte "personenname" ein. In der ersten neuen Spalte
möchten wir nun nur den Personennamen einfügen. Wir klicken in das Feld
B2 und geben die benötigte Funktion ein: =LINKS(A2;FINDEN(",";A2)-1)
(d.h.: "Gebe den Text der Zelle A2 von links beginnend aus, bis ein
Komma gefunden wird, breche dort ab und entferne jeweils das letzte
Zeichen, also das Komma."). Über das schwarze Quadrat rechts unten in
der Zelle lässt sich die Funktion über die darunter liegenden Zellen
ziehen und somit im Masseverfahren anwenden.
- In ähnlicher Weise verfahren wir für den Titel der Person: Wir klicken in das Feld C2 und geben die benötigte Funktion ein: =RECHTS(A2;LÄNGE(A2)-FINDEN(",";A2)) (d.h.: "Gebe den Text der Zelle A2 aus, beginnend jedoch erst ab dem Komma."). Wir ziehen die Funktion wie gehabt über die darunter liegenden Zellen auf.
- Wenn wir nun auf die neu befüllten Zellen klicken, wird die eingegebene Formel angezeigt. Wenn wir den Inhalt von den Formeln trennen möchten, markieren wir die betroffenen Zellen → Rechtsklick → "Nur Inhalte einfügen" → mit OK bestätigen.
- Abschließend löschen wir die Ausgangsspalte "personenname" und ergänzen entsprechende Titel ("personenname", "titel") bei den neu hinzugefügten Spalten.
- 2. Die zweite (und in diesem Fall bequemere) Möglichkeit, um Inhalte in Zellen zu trennen, wenden wir auf die Spalte "begraebnisstaette" an: Zunächst fügen wir rechts neben der Spalte eine neue Spalte ein. Wir markieren die Spalte "begraebnisstaette" durch Klick auf den Spaltenkopf → Menü "Daten" → "Text in Spalten" → Trennoption "Komma" → mit OK bestätigen. Abschließend vergeben wir noch den neuen Spaltennamen "ort". Ebenso verfahren wir zu guter Letzt bei der Spalte "geokoordinaten" und ändern bzw. vergeben die Spaltennamen "geokoordinate1" und "geokoordinate2".
- 1. Einsatz einer Funktion: Wir fügen zunächst zwei leere Spalten
rechts neben der Spalte "personenname" ein. In der ersten neuen Spalte
möchten wir nun nur den Personennamen einfügen. Wir klicken in das Feld
B2 und geben die benötigte Funktion ein: =LINKS(A2;FINDEN(",";A2)-1)
(d.h.: "Gebe den Text der Zelle A2 von links beginnend aus, bis ein
Komma gefunden wird, breche dort ab und entferne jeweils das letzte
Zeichen, also das Komma."). Über das schwarze Quadrat rechts unten in
der Zelle lässt sich die Funktion über die darunter liegenden Zellen
ziehen und somit im Masseverfahren anwenden.
Anmerkungen
Einstieg Datenstrukturierung
(//Abbildung der vorangehenden, bereinigten Calc-Datei einbinden)
Besprechung ausgewählter Teilnehmer-Tabellen
Bei der vorangehenden Übung haben wir damit begonnen, Inhalte sauber
strukturiert abzulegen und Informationen auf verschiedene
Tabellenspalten sinnvoll aufzugliedern.
Vorbereitend zu
dieser Sitzung, sollten die Teilnehmer einen Abschnitt aus der Liste
nach Lauro (ges. 10 Personen) sinnvoll strukturieren. Im Folgenden
werden drei der Einsendungen als ausgewählte Beispiele besprochen:
Datei 1:
- Geographisch gegliedert (Je ein Tabellenblatt/Land, darin den entsprechenden Verwaltungsebenen die Begräbnisstätten zugeordnet und diesen wiederum die Personen samt Lebensdaten)
- Für eine überschaubare Anzahl an Personen mag dieses Verfahren noch anwendbar sein; sobald jedoch die Zahl der Datensätze ansteigt, wird es hier schnell unübersichtlich
- Rudolf Franz (1822-1822) wird an zwei verschiedenen Orten begraben. Es wäre daher sinnvoll, die Personen separat zu sammeln und sie über einen Identifier mit den entsprechenden Grabstätten zu verknüpfen → Redundanz vermeiden, da fehleranfällig und mit Mehraufwand verbunden bei Überarbeitung
- Ferner wird es in vorliegendem Beispiel schwierig, die einzelnen Objekten mit Zusatzinformationen anzureichern (z.B. Wikipedia-Artikel); diese müssten hier ebenfalls mehrfach eingetragen werden.
- Daten sind nicht quantifizierbar. In der vorliegenden Form könnten keine statistischen Auswertungen erfolgen.
Datei 2:
- Datei 2 besteht aus einer Haupttabelle und einer Nebentabelle mit ergänzenden Informationen. Positiv hervorzuheben ist, dass Informationen auf verschiedene Spalten aufgeteilt werden und jede Zeile dabei einen Datensatz darstellt. Den Personen werden Informationen zur Grabstätte sowie Normdaten (GND) beigegeben
- Positiv ist ebenfalls die Strukturierung der Daten, wenngleich in manchen Fällen nicht unbedingt erforderlich (z.B. könnten Name und Zusatz in einer Spalte zusammengefasst werden)
- Verbesserungswürdig ist Verknüpfung der Informationen; diese erfolgt in diesem Beispiel über die Geokoordinaten, welche in Tabelle 2 um den jeweiligen Ort ergänzt werden. Zielführend wäre der Einsatz von IDs.
- Problematisch ist ebenfalls die Redundanz der eingetragenen Daten, insb. der Geodaten.
Datei 3:
- Dieser Teilnehmer hat seine Daten in verschiedenen Tabellen abgelegt und diese durch den Einsatz von IDs miteinander in Verbindung gesetzt.
- Informationen werden dadurch quantifizierbar
- In einigen Fällen könnte noch stärker normalisiert werden (z.B. Trennung Name und Lebensdaten), in anderen Fällen geht die Aufteilung der Informationen etwas über das Ziel hinaus (z.B. Ort und Land → in eine Tabelle)
- Zuordnung der Sakralbauten und Grabstätten erscheint problematisch: Wird eine Person an mehreren Orten begraben, so werden zwar "Gruft" und "Sakralbau" genannt, jedoch nur eine Ortsangabe. Eine georeferenzierte Darstellung wäre in diesen Fällen nicht möglich.
Einstieg in die Datenstrukturierung
→ Für umfassende Informationen sei auf "Das relationale Datenmodell I" verwiesen.
In den gezeigten Beispielen
gibt es gute Ansätze zur Strukturierung der Forschungsdaten. Jedoch
tritt zuweilen eine noch recht "geisteswissenschaftliche Vorstellung"
von Tabellen zutage, d.h. es gilt noch stärker zu verstehen, warum Daten
strukturiert in verschiedenen Tabellen und Spalten abgelegt werden
sollten und auf welche Art und Weise dies in einer relationalen
Datenbank erfolgt.
>Warum werden Daten in
verschiedenen Tabellen abgelegt?
- Vermeidung von Redundanz - Stichwort: Normalisieren, d.h. Daten sollten möglichst nicht wiederkehrend, sondern an zentraler Stelle einmalig abgelegt werden. Dadurch wird sichergestellt, dass
- die Konsistenz der Daten erhalten bleibt; eine Änderung am Datenbestand muss also nur an einer Stelle durchgeführt werden. In manchen der oben angeführten Beispiele müsste man bei der Änderung einer Information an verschiedenen Stellen suchen und die Ausbesserung vornehmen
- die Datenmenge übersichtlich und überschaubar bleibt.
- möglichst viele Zusatzinformationen an nur einer Stelle in der Datenbank eingebettet werden können.
Zur Einbindung der Informationen in andere Tabellen
werden eindeutige Schlüssel (ID) verwendet bzw. eigene Tabellen
angelegt, die nur zur Zuordnung verschiedener Objekte und Merkmale
dienen. Die Verknüpfung erfolgt stets über die ID, die jeden Datensatz,
d.h. jede Zeile einer Tabelle eindeutig identifizierbar macht.
Ein guter Ansatzpunkt um festzustellen, an welcher
Stelle ein weiteres Aufsplitten von Informationen sinnvoll sein könnte,
ist das Sortieren nach bestimmten Informationen. In manchen der oben
angeführten Beispiele wäre es zum Beispiel nicht möglich, nach den
Geburts- oder Sterbejahren zu sortieren, wenn sich diese in derselben
Spalte wie der Personenname befindet. Dadurch wird auch die
Quantifizierbarkeit der Informationen negativ beeinflusst, da z.B. nicht
danach gefiltert werden kann, wie viele Personen im Zeitraum XXXX-YYYY
gestorben sind.
Um sich Klarheit über die
Datenbasis und ihre sinnvolle Strukturierung noch vor der Erstellung der
späteren Datenbank zu verschaffen, hilft die Anlage eines sogenannten
Entity-Relationship-Modells (ERM). Dieses wird in der folgenden Sitzung
theoretisch erklärt und praktisch anhand der besprochenen Beispieldaten
umgesetzt.
Datenstrukturierung, Teamorganisation I
Entity-Relationship-Modell - Theorie
In der vorangehenden Sitzung wurde die Bedeutung für die strukturierte und normalisierte Erfassung von Forschungsdaten dargelegt. Die Anlage eines Entity-Relationship-Modells (ERM) unterstützt in der konzeptionellen Phase eines Datenbankprojekts die Erstellung des Datenbank-Designs.
- Modellhafte Beschreibung der zu verarbeitenden Daten und ihrer Beziehungen zueinander
- Welche Objekte stehen im Erkenntnisinteresse und welche Beziehungen zwischen diesen Objekten besitzen Relevanz? (Personen, Grabstätten, Orte, Vorfahren etc.)
- Auf welche Weise sollen die Objekte und ihre Beziehungen dargestellt werden?
- Welchen Erkenntnisinteressen soll unsere Datensammlung dienlich sein?
→ Ein Datenmodell gibt Antworten auf diese Fragen. Als theoretische Grundlage eines Datenbanksystems beschreibt ein Datenmodell, auf welche Weise Daten in einem Datenbanksystem abgespeichert und verarbeitet werden sollen. Es ist leicht verständlich, daher dient es als gute Kommunikationsbasis zwischen Anwendern und Entwicklern. Dadurch hat sich das ER-Modell zum De-facto-Standard für die Datenmodellierung etabliert. Es besitzt folgende grundlegende Komponenten:
- Entität: Objekt (z.B. eine Person, ein Begräbnisort) ⇒ dargestellt als Rechteck
- Attribut: bestimmte Eigenschaften die eine Entity besitzt ⇒ dargestellt als Kreis
- Relation: Beziehung zwischen Objekten ⇒ dargestellt als Raute
Objekte können unterschiedliche Arten von Beziehung zueinander besitzen:
- 1:1-Beziehungen: Jedem Datensatz aus einer Tabelle A ist genau ein Datensatz aus einer Tabelle B zugeordnet und umgekehrt. Diese Art von Beziehung tritt eher selten auf. ⊕ Unser Beispiel: eine Grabstätte, die einer Kategorie zugeordnet wird (z.B. Gruft, Dom)
- 1:n-Beziehungen: Jedem Datensatz aus einer Tabelle A können beliebig viele passende Datensätze aus einer Tabelle B zugeordnet werden, jedoch umgekehrt nur ein Datensatz aus Tabelle B einem Datensatz aus Tabelle A. Diese Form der Beziehung tritt am häufigsten auf. ⊕ Unser Beispiel: eine Grabstätte kann nur an einem Ort sein, aber an einem Ort können mehrere Grabstätten sein
- n:m-Beziehungen: Jedem Datensatz aus einer Tabelle A können beliebig viele passende Datensätze aus einer Tabelle B zugeordnet werden und umgekehrt. Dies erfolgt über eine dritte, zu erstellende Tabelle, in der zur eindeutigen Zuordnung die Primärschlüssel der jeweiligen Datensätze in Verbindung gesetzt werden. ⊕ Unser Beispiel: Einer Person können mehrere Gräber zugeordnet werden und in einem Grab können mehrere Personen liegen
Entity-Relationship-Modell - Praxis
Zur Anlage eines ERM eignet sich der Diagrammeditor Dia (Start →
Anwendungen → Grafik). Dort können auf intuitive Weise die oben
genannten Bestandteile eines ERM (Rechtecke, Rauten, Kreise) sowie
Verbindungslinien erstellt werden. Diese können mit beschreibenden
Texten versehen werden (Objektbezeichner, Beziehungsarten). Änderungen
können durch Verschieben der einzelnen Elemente leicht erfolgen,
Verknüpfungen zwischen Elementen bleiben dabei erhalten. Neue Objekte
oder Verknüpfungen lassen sich jederzeit ergänzen. Das erstellte ERM
kann anschließend als Bilddatei (Datei → Diagramm exportieren) im
PNG-Format exportiert werden.
Gemeinsam mit den Teilnehmern
wurde auf Grundlage der Beispieldaten der vergangenen Sitzung ein ERM in
Dia erstellt.
Beschreibung:
- Zwei zentrale Objekte in unserer Datensammlung sind die Personen und ihre Begräbnisstätten
- Beiden Objekten können je nach Forschungsinteresse beliebig viele Zusatzinformationen zugeordnet werden (Attribute)1
- In Beziehung zueinander werden sie durch eine Verknüpfungstabelle gesetzt (Relation)
- Die Verknüpfung wird wiederum durch Attribute angereichert, die die Art des Begräbnisses näher spezifiziert
- Es handelt sich hierbei um eine n:m-Beziehung, da manche Personen an verschiedenen Stätten begraben sind. Die Bestattungsart definiert, welcher Bestandteil der Person wo begraben liegt.
- Um Redundanz zu vermeiden, werden die Orte samt ihnen zugehörigen Informationen in eine eigene Tabelle ausgelagert und über ihre ID in die Tabellen "grabstaette" (Ort, an dem sich die Grabstätte befindet) sowie "personen" (Geburts- und Sterbeort) eingebunden
- Für die Darstellung auf der Karte werden Geokoordinaten benötigt; da wir die Begräbnisstätten visualisieren möchten, sind ihnen die exakten Koordinaten in der entsprechenden Tabelle zuzuordnen
- Alle Personen werden zentral in der entsprechenden Tabelle abgelegt, unabhängig davon, ob es sich um Primärpersonen (Angehörige der Habsburger Dynastie) oder Sekundärpersonen (angeheiratete Personen, die in der Liste nur am Rande angeführt werden) handelt.
- Die Beziehung unter den Personen (Ehe, Eltern-Kind) wird in einer eigenen Verknüpfungstabelle vorgenommen. Für die Art der Beziehung stehen verschiedene Optionen zur Auswahl.
Aus diesem ERM ergeben sich demnach folgende Tabellen, die
gleichzeitig auch bereits einen Eindruck von unserer anzulegenden
Datenbank vermitteln:
- 'personen'
- 'grabstaette'
- 'ort'
- 'begraben'
- 'beziehung'
Diskussion
Diskussion der Modellierung inhaltlicher Aspekte in den einzelnen Tabellen:
- Personen: Welcher Herrschertitel soll eingetragen werden? → höchste, erreichte Titel (z.B. röm.-dt. Kaiser)
- Personen: Wie wird bei unsicheren Datumsangaben verfahren? → Ergänzung einer eigenen Spalte, in der angegeben wird, ob das Jahr als sicher oder unsicher angenommen werden kann. Sofern zwei konkurrierende, aber exakte Datumsangaben bestehen, werden diese in zwei verschiedene Spalten eingegeben.
- Personen: Normdaten: Als sinnvoll erachtet werden GND-Nummer, Kaiserhof-ID (für die spätere Verknüpfung beider Angebote), Wikidata-Datenobjekt ("Q-ID")
- Ort: Welche Zusatzangaben zu den Orten sollen ergänzt werden? (Verwaltungsebene, Staat, frühere Bezeichnung)
- Ort: Eindeutige Ortsnamen bei Orten mit gleichem Namen (z.B. Ergänzungen in Klammern)
- Grabstätte: Es gilt zu entscheiden, in welche Kategorien die Grabstätten (Gruft, Friedhof, etc.) eingeteilt werden können; alternativ oder parallel dazu könnte auch die Art des Grabes kategorisiert werden (Tumba, Erdgrab, etc.)
- begraben: Begräbnisdatum ermitteln; wie ist mit Fällen umzugehen, in denen eine Person umgebettet wurde?
- Allgemein: Welche gemeinfreien Abbildungen stehen zur Verfügung (Personen, Grabstätten)? → Kaiserhof, Wikipedia, Portraitindex(?)
Teamorganisation
Zur Teamorganisation und zur Sammlung von Ideen, Informationen und Problemfällen wurde zunächst eine Arbeitsumgebung auf dh-lehre eingerichtet. Ergänzt wurde dies in der Folge durch ein Google Doc, in dem alle zentralen Aspekte durch die Teilnehmer gesammelt und beschrieben wurden. Dieses Dokument dient in der Folge auch als Grundlage für Ausarbeitung einer Dokumentation des Datenbankprojekts im Rahmen der Veröffentlichung.
Anmerkungen
- In der vorliegenden Darstellung wurden aus Platzgründen nicht alle Personen-Attribute, wie z.B. Geburts- und Sterbeort, angeführt.↩︎
Einstieg in phpMyAdmin
In den vorangehenden Sitzungen wurden Grundlagen zur Modellierung von
Forschungsdaten und ihrer Strukturierung (ER-Diagramm) vermittelt.
Nachdem unsere Daten nun in sauberer Form in Calc-Tabellen vorliegen,
können wir in einem nächsten Schritt die Datensammlungen in eine
Datenbank importieren.
Eine theoretische Einführung in
relationale Datenbanken findet sich im entsprechenden Abschnitt des
Handbuchs1. Es wird empfohlen,
zunächst dort
einen Blick hineinzuwerfen, bevor Sie die Lektüre fortsetzen.
Für die Verwaltung und Verarbeitung unserer anzulegenden Datenbank
verwenden wir die grafische Benutzeroberfläche phpMyAdmin.
Erkunden der phpMyAdmin-Benutzeroberfläche
Mit der Anmeldung im DHVLab wurde für Sie automatisch eine
persönliche Datenbank angelegt. In dieser Datenbank können Sie ab sofort
Tabellen anlegen, Daten importieren/exportieren und modellieren. Um
diese Schritte möglichst komfortabel durchführen zu können, empfiehlt
sich die Verwendung der Benutzeroberfläche phpMyAdmin. Der Zugriff auf
phpMyAdmin ist über den Browser des Virtuellen Desktops möglich. Öffnen
Sie hierzu den Browser und geben Sie in die Adresszeile ein2:
web.dmz.dhvlab.fo/sql
Melden Sie sich wie
gewohnt mit Ihren Benutzerdaten an. Erkunden Sie zunächst die
Benutzeroberfläche. Einen nützliche Beschreibung finden Sie im
zugehörigen Abschnitt des Handbuchs3.
Import einer Tabelle
Beachten Sie stets, in welcher Navigationsebene Sie sich aktuell
befinden, bevor Sie auf "Importieren" klicken. Die zu importierende
Datei wird genau dort eingefügt. Wählen Sie eine Datei aus, die Sie
importieren möchten. Wählen Sie dann das Format der ausgewählten Datei
aus. Wenn Sie als Dateiformat CSV auswählen, müssen Sie bei den nun
angezeigten "Formatspezifischen Optionen" noch spezifizieren, durch
welches Zeichen die einzelnen Spalten in der Datei getrennt werden (z.B.
",", ";", "\t"). Um dies zu ermitteln, werfen Sie zuvor mit einem
Texteditor einen Blick in die CSV-Datei. Mit Klick auf "OK" schließen
Sie den Import der Tabelle ab. Sie wird an der entsprechenden Stelle in
der linken Auflistung angeführt.
Anwendungsfall:
- Im Ordner "courses → grabdenkmaeler → liegt die Datei "personen.xls". Speichern Sie eine Kopie dieser Datei in ihrem "Persönlichen Ordner" des Virtuellen Desktops.
- Wandeln Sie die Datei in das CSV-Format um
- Löschen Sie eine ggf. vorhandene "ID"-Spalte
- Öffnen Sie die Datei in einem Texteditor Ihrer Wahl (z.B. KATE), um zu sehen, welcher Separator verwendet wird (hier: Komma)
- Wählen Sie in phpMyAdmin Ihre Datenbank (labuser_ihrname) an. Gehen Sie anschließend auf "Importieren". Wählen Sie dort die Datei an, als Format "CSV", und setzen Sie einen Haken bei der Option "Die erste Zeile der Datei enthält die Spaltennamen". Bestätigen Sie anschließend mit OK.
- Wählen Sie anschließend Ihre neu eingefügte Tabelle an und gehen Sie in den Bereich "Struktur". Dort können Sie nun eine ID-Spalte ergänzen (Typ: INT; Länge 10; Haken setzen bei "AI" (Auto Increment)), die den Datensätzen automatisch ihre ID zuweist.
- Abschließend können Sie bei den anderen Spalten noch den jeweiligen Spaltennamen ändern sowie den Datentyp (VARCHAR, INT samt Länge). Der Datentyp definiert, welche und wie viele Zeichen in einer Spalte vorkommen dürfen4.
Export einer Tabelle
Wählen Sie nun die eben importierte Tabelle an, um Sie wiederum aus der Datenbank zu exportieren. Klicken Sie anschließend auf "Exportieren" in der operativen Ebene. Bei "Art des Exports" können Sie es in der Regel "Schnell - nur notwendige Optionen anzeigen" belassen. Bei "Format" können Sie zwischen einer Reihe an Ausgabeformaten wählen. Sinnvollerweise speichern Sie Ihre Ausgabe entweder als SQL-File oder als CSV und wählen Ihren persönlichen Ordner als Speicherort.
Anlegen einer neuen Tabelle
Es gibt neben dem Import von Tabellen natürlich auch die Möglichkeit,
diese unmittelbar in phpMyAdmin anzulegen. Dies erfolgt auf zwei
verschiedene Arten, entweder manuell über die intuitive
Benutzeroberfläche oder durch Eingabe des entsprechenden SQL-Befehls5.
Anwendungsfall "via
Benutzeroberfläche" (Ortstabelle):
- Wählen Sie Ihre persönliche Datenbank an
- Klicken Sie auf "Neu" und geben alle gewünschten Informationen zur Tabellenstruktur in die dafür vorgesehenen Felder ein: Tabellenname ("ort"); Spaltennamen ( 1) ort_id, 2) name, 3) name_alt, 4) verwaltungsebene, 5) staat) und Datentypen+Werte ( 1) INT, 10; "AI", Index: "Primary"; 2)-5) VARCHAR, 300, Kollation: utf-8-general-ci).
- Bestätigen Sie mit "Speichern"
Anwendungsfall "SQL" (Grabstätten):
- Wählen Sie Ihre persönliche Datenbank an
- Klicken Sie in der operativen Ebene auf "SQL"
- Geben Sie in die SQL-Eingabemaske folgendes SQL-Statement ein:
CREATE TABLE grabstaette (grabstaette_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, name VARCHAR(550), ort_id INT(11), kategorie_id INT(11), geokoordinate1 DECIMAL(10,7), geokoordinate2 DECIMAL(10,7), abbildung VARCHAR(550), wikipedia VARCHAR(550));
Einfügen eines neuen Datensatzes
Sie können in Ihre neu angelegte Tabelle nun nach Belieben neue
Datensätze hinzufügen, bestehende überarbeiten oder löschen. Dies
erfolgt wiederum über die intuitiv gestaltete Benutzeroberfläche.
Anwendungsfall "Datensatz einfügen":
- Sie möchten einen Datensatz zur Abtei Heiligenkreuz in ihrer Tabelle "Grabdenkmaeler" ergänzen.
- Wählen Sie die Tabelle an und klicken Sie in der operativen Ebene auf "Einfügen"
- Geben Sie Ihre Werte in die dafür vorgesehenen Felder ein (name: "Abtei Heiligenkreuz", id_ort: "1", id_kategorie: "2", geokoordinate1: "48.0553340", geokoordinate2: "16.1308230", abbildung: "", wikipedia: "Q697221", link_alt: "")
Übungsaufgaben
- Importieren Sie die Tabelle "ort" aus dem Kursordner in Ihre
persönliche DB (Hinweis: Kopieren Sie die Datei zunächst aus dem Ordner
auf Ihren virt. Desktop!).
- Fügen Sie anschließend einen Datensatz (München, Bayern, Deutschland) hinzu.
- Löschen Sie den Datensatz zu "Wiener Neustadt" aus Ihrer Tabelle.
- Ändern Sie beim Eintrag "Heiligenkreuz" das Land zu "Timbuktu".
- Im Kursordner befindet sich der Unterordner "Muster". Darin finden Sie alle Muster-Tabellen, die im Kursrahmen besprochen wurden. Legen Sie mit Hilfe des erlernten SQL-Befehls eine neue Tabelle an und orientieren Sie sich bei der Struktur an einer der Muster-Tabellen6.
Anmerkungen
- Siehe die Abschnitte "Das relationale Datenmodell - Theoretische Grundlagen I" sowie "Das relationale Datenmodell - Theoretische Grundlagen II".↩︎
- Es ist auch möglich, die Datenbankumgebung außerhalb des Virtuellen Desktops, über folgende Adresse zu öffnen: Datenrepositorium↩︎
- Siehe Abschnitt "Praktischer Einstieg in phpMyAdmin".↩︎
- Für eine Übersicht über die gängigen Datentypen sowie Grundlegendes zur Anpassung der Tabellenstruktur vgl. das zuvor genannte Handbuch.↩︎
- SQL steht für Structured Query Language. Wir werden ihre Struktur und Funktionsweise im weiteren Verlauf ausführlich behandeln.↩︎
- Der Lernerfolg der Studierenden kann über die Benutzeroberfläche von phpMyAdmin nachvollzogen werden, da der/die Kursleiter/in Zugriff auf alle TN-Datenbanken besitzt.↩︎
Einstieg in SQL
SQL: Theoretische Vorbemerkung
Im vorangehenden Abschnitt haben wir uns mit der Oberfläche des DBMS phpMyAdmin und ihren zentralen Funktionen (Import/Export, Anlegen neuer Tabellen, Einfügen und Bearbeiten von Datensätzen) vertraut gemacht. Dabei sind wir an einer Stelle bereits mit der Datenbanksprache SQL in Kontakt gekommen. Im Folgenden werden wir uns mit den Grundzügen dieser für uns sehr wichtigen Sprache auseinandersetzen1. Die Abfragen/Befehle der Datenbanksprache SQL lassen sich in drei Kategorien unterteilen:
- Data Control Language (DCL)2
- Data Definition Language (DDL)
- Data Manipulation Language (DML) (wichtigste SQL-Bereich für Sie als Kursteilnehmer)
Praktischer Einstieg in SQL
DDL
Mit DDL können Veränderungen verschiedener Art an der bestehenden
Tabellenstruktur vorgenommen werden. Hierfür kommt das Statement "ALTER"
zum Einsatz, beispielsweise um eine Tabellenspalte zu ergänzen oder zu
löschen:
~ ALTER TABLE personen_sqluebung ADD sterbejahr_alt
varchar(4) AFTER sterbejahr
→ Die Tabelle
'personen_sqluebung' wird um eine Spalte namens 'sterbejahr_alt' mit
einer Länge von vier Zeichen ergänzt. ~ ALTER TABLE personen_sqluebung
DROP COLUMN sterbejahr_alt
→ Die Spalte 'sterbejahr_alt'
wird aus der Tabelle 'personen_sqluebung' entfernt.
DML - SELECT
Die Datenbearbeitungssprache DML ermöglicht uns das Auswählen
(SELECT), Einfügen (INSERT INTO), Ändern (UPDATE) und Löschen (DELETE
FROM/TRUNCATE TABLE) von Daten innerhalb von Tabellen. Der "SFW"-Block
(SELECT, FROM, WHERE) bzw. die "WHERE-Klausel" erlauben eine Selektion
einzelner Zeilen aus einer Tabelle, deren Inhalte einem bestimmten
Muster entsprechen3.
Anwendungsfall 1:
~ Geben Sie Funktion, Name und Geburtsjahr
aller Personen aus, die zwischen 1200 und 1500 geboren wurden.
→ SELECT funktion, name, geburtsjahr FROM personen_sqluebung WHERE
geburtsjahr >= "1200" AND geburtsjahr <= "1500"
Anwendungsfall 2:
~ Geben Sie Funktion, Name und
Geburtsjahr aller Personen aus, die zwischen 1200-1209 und 1500 geboren
wurden.
→ SELECT funktion, name, geburtsjahr FROM
personen_sqluebung WHERE geburtsjahr >= "120_" AND geburtsjahr <=
"1500"
_ genau ein beliebiges Zeichen trunkieren
% beliebig große Anzahl an Zeichen trunkieren
Anwendungsfall 3:
~ Geben Sie Funktion, Name und
Geburtsjahr aller Personen aus, die zwischen 1200 und 1500 geboren
wurden, sortiert nach dem Geburtsjahr in absteigender Reihenfolge:
→ SELECT funktion, name, geburtsjahr FROM personen_sqluebung WHERE
geburtsjahr >= "1200" AND geburtsjahr <= "1500" ORDER BY
geburtsjahr DESC
Ohne den Zusatz DESC erfolgt
die Sortierung immer aufsteigend (ASC)
Anwendungsfall 4:
~ Verwendung von sog.
"Korrelationsnamen", wenn man Spaltennamen mit alternativem Namen
ausgeben möchte. Dies ist insbesondere dann sinnvoll, wenn man mehrere
Tabellen miteinander verknüpft, die ähnliche oder gleiche Spaltennamen
besitzen (z.B. "name" → "Herrschername")
→ SELECT funktion
"Titel", name "Herrschername", geburtsjahr FROM personen_sqluebung WHERE
geburtsjahr >= "1200" AND geburtsjahr <= "1500"
DML - INSERT INTO
~ Einfügen eines oder mehrerer Datensätze in eine bestehende
Tabelle:
→ INSERT INTO `personen_sqluebung` (`funktion`,
`name`) VALUES (Fürst, Franz), (Kaiserin, Sissi)
Es müssen
nicht alle Tabellenfelder befüllt werden; die Felder, welche befüllt
werden sollen, müssen genannt werden.
~ Import
von Datensätzen aus einer Tabelle 1 in eine Tabelle 2:
→
INSERT INTO tabelle2 (id, spalte2, spalte3) SELECT id, spalte2, spalte3
FROM tabelle1 WHERE id < 2;
DML - UPDATE
~ Aktualisierung eines Wertes in einer bestehenden Tabelle:
→ UPDATE `personen_sqluebung` SET geburtsjahr = "1837" WHERE name
= "Sissi"
~ UPDATE, mehrere Spalten betreffend: → UPDATE
`personen_sqluebung` SET geburtsjahr = "1837", sterbejahr = "1900" WHERE
name = "Sissi"
DML - DELETE
~ Löschen von Inhalten, beispielsweise nach einem fälschlicherweise
ausgeführten INSERT INTO-Statement, bei dem in der Folge alle Einträge
ab einer bestimmten ID gelöscht werden müssen:
→ DELETE FROM
`personen_sqluebung` WHERE id_person > 29
Übungsaufgaben
Zur Anwendung des Erlernten bearbeiten Sie bitte folgende SQL-Übungsaufgaben:
- Geben Sie aus der Tabelle "personen_sqluebung" alle weiblichen Personen aus!
- Geben Sie aus der Tabelle "personen_sqluebung" alle Personen aus, deren Name mit dem Buchstaben "R" beginnt!
- Geben Sie aus der Tabelle "personen_sqluebung" alle Personen aus, bei denen es sich entweder um einen König oder Kaiser handelt.
- In der Kursdatenbank befindet sich die Tabelle "personen_zusatz". Sie möchten die Datensätze dieser Tabelle in die Tabelle "personen_sqluebung" importieren (Name, Funktion, Geburts- und Sterbejahr). (Hinweis: Kopieren Sie die Tabelle "personen_zusatz zunächst in Ihre persönliche DB)
- Benennen Sie "Rudolf III. (I.)" (ID = 5) um in "Rudolf I.". Verwenden Sie hierzu einen UPDATE-Befehl.
- Löschen Sie die letzten drei Datensätze aus Ihrer Personen-Tabelle (ID's 27, 28, 29)
Bitte senden Sie zur Überprüfung des Lernerfolges die hierfür benötigten SQL-Abfragen Ihrem Kursleiter zu.
Anmerkungen
- Für einen umfassenden Einstieg in die Datenbanksprache SQL vgl. den entsprechenden Abschnitt im Handbuch "Erlernen einer Datenbanksprache: Structured Query Language (SQL) I".↩︎
- Auf DCL wird an dieser Stelle nicht weiter eingegangen, da sie nicht zum "alltäglichen Handwerkszeug" des Datenbanknutzers gehört (z.B. User-Rechte-Vergabe).↩︎
- Für die Erklärung des Aufbaus einer Datenbankabfrage vgl. den Abschnitt Grundform einer Datenbankanfrage im Handbuch: Erlernen einer Datenbanksprache: Structured Query Language (SQL) I↩︎
Joins, Teamorganisation II
Ergebnisse der Übungsaufgaben
→ SELECT * FROM personen_sqluebung WHERE geschlecht = 'w'
→ SELECT * FROM personen_sqluebung WHERE name LIKE 'R%'
→ SELECT * FROM personen_sqluebung WHERE function = 'König' OR
function = 'Kaiser'
Ergänzung zu
Abfrageergebnissen:
- Abfrageergebnisse werden stets als neue Tabelle ausgegeben und sind beliebig weiter verarbeitbar
- Abfrageergebnisse können exportiert werden und andernorts wiederum importieren
→ INSERT INTO `personen_sqluebung`(`name`, `funktion`,
`geschlecht`, `geburtsjahr`, `sterbejahr`) SELECT `herrscher`, `titel`,
`geschlecht`, `geburtsjahr`, `todesjahr` FROM `personen_zusatz`
Hinweis: Es ist nicht zwingend erforderlich, die
Tabelle zunächst in die eigene Datenbank zu kopieren. Es können
Datensätze auch aus einer anderen Datenbank (hier: Kursdatenbank)
importiert werden; hierzu muss die Datenbank entsprechend gekennzeichnet
werden, was durch Datenbankname.Tabellenname (durch einen Punkt
verbunden) erfolgt.
→ INSERT INTO
`personen_sqluebung`(`name`, `funktion`, `geschlecht`, `geburtsjahr`,
`sterbejahr`) SELECT `herrscher`, `titel`, `geschlecht`, `geburtsjahr`,
`todesjahr` FROM `lab_grabdenkmaeler.personen_zusatz`
→
UPDATE `personen` SET name = "Rudolf I." WHERE id_person = 5
→ DELETE FROM personen_sqluebung WHERE id_person > 26
Verknüpfung von Tabellen: Joins
Bisher haben wir immer nur mit einer Tabelle gearbeitet. Das Potential relationaler Datenbanken kommt aber erst zur Geltung, wenn man die vorher fein säuberlich getrennten Daten nun wieder in Verbindung setzt - und das erfolgt mit sogenannten Joins1. Bildlich gesprochen werden mehrere Tabellen nebeneinander gelegt. Wir unterscheiden verschiedene Arten von Joins:
- INNER JOIN
- LEFT JOIN/RIGHT JOIN
- OUTER JOIN
Anwendungsfall "INNER JOIN":
~ Sie möchten die
Grabstätten samt ihrer zugehörigen Orte in einer Tabelle ausgeben,
jedoch nur den Namen der Grabstätte, ihre Geokoordinaten, den Ortsnamen
und den Staat.
→ SELECT name, geokoordinate1,
geokoordinate2, ortsname, staat FROM grabstaette INNER JOIN ort ON
(grabstaette.id_ort = ort.id_ort)
Anwendungsfall "LEFT JOIN":
Bei einem LEFT JOIN werden alle
Datensätze der "linken" Tabelle ausgegeben, auch wenn sie in der
"rechten" Tabelle keine Entsprechung aufweisen. Die Datensätze der
rechten Tabelle werden dagegen nur mit ausgegeben, wenn sie eine
Entsprechung aufweisen, ansonsten wird das entsprechende Feld mit NULL
ausgegeben. ~ Sie möchten sich alle Grabstätten anzeigen lassen und die
zugehörigen Orte, sofern diese bereits vorhanden sind. Fälle, in denen
der Ort nicht vorhanden ist, werden mit NULL ausgegeben. Damit können
Sie sich einen Überblick verschaffen, wo noch nach Orten gesucht werden
muss.
→ SELECT grabstaette.name, ort.ortsname FROM
grabstaette LEFT JOIN ort ON grabstaette.id_ort = ort.id_ort
Anwendungsfall "RIGHT JOIN":
Beim RIGHT
JOIN verhält es sich gegensätzlich zum LEFT JOIN, d.h. hier wird die
Haupttabelle "grabstaette" mit der Tabelle ort "rechts herum" verbunden.
Hier werden also alle Datensätze der rechten Tabelle (ort) angezeigt und
fehlende der linken Tabelle (grabstaette) mit NULL ausgefüllt.
~ Sie möchten sich alle Orte anzeigen lassen und die zugehörigen
Grabstätten, sofern diese bereits vorhanden sind. Fälle, in denen die
Grabstätte nicht vorhanden ist, werden mit NULL ausgegeben.
→ SELECT grabstaette.name, ort.ortsname FROM grabstaette LEFT JOIN ort
ON grabstaette.id_ort = ort.id_ort2
Anwendungsfall "OUTER JOIN":
Beim OUTER JOIN handelt es sich
um eine Kombination aus einem LEFT- und einem RIGHT JOIN. Es werden alle
Datensätze beider Tabellen ausgegeben, bei Übereinstimmung werden sie
verknüpft, ansonsten wie gehabt mit NULL wiedergegeben. Da SQL keinen
genuinen OUTER JOIN unterstützt, muss mit einem UNION-Statement
nachgeholfen werden (= Verknüpfung des Ergebnisses zweier Abfragen) ~
Sie möchten sich alle Grabstätten und alle Orte in einer Tabelle
ausgeben lassen, auch wenn diese keine jeweilige Verknüpfung zueinander
vorweisen können.
→ SELECT grabstaette.name, ort.ortsname
FROM grabstaette LEFT JOIN ort ON grabstaette.id_ort = ort.id_ort UNION
SELECT grabstaette.name, ort.ortsname FROM grabstaette RIGHT JOIN ort ON
grabstaette.id_ort = ort.id_ort
Fortsetzung: Datenstrukturierung unseres Mapping-Projekts
Wie finde ich heraus, ob die Person, der Ort oder die Grabstätte schon eingetragen wurde?
- Immer zunächst nachsehen, ob der Eintrag bereits vorhanden ist!
- Jedes Objekt wird stets nur einmal erfasst, d.h. wenn es schon vorhanden ist, umso besser!
- Tipp Orte/Personen: Auf den Spaltennamen "name" in der Tabelle "ort"/"personen" klicken; mit der alphabetischen Sortierung lässt sich idR rasch ermitteln, ob der Ort/die Person schon vorhanden ist oder nicht.
- Tipp Grabstätten: Hier hilft uns eine alphabetische Sortierung nur bedingt, da der Name in manchen Fällen von dem bei Lauro abweicht. Daher bietet es sich an, nach der Orts-ID zu sortieren. Daraufhin kann man anhand des bei Lauro angegebenen Ortes in der Ortstabelle die Orts-ID ermitteln und ihrer Hilfe wiederum in der Tabelle "grabstaette" überprüfen, ob die gesuchte Grabstätte bereits eingetragen wurde oder nicht.
- Tipp allgemein: “Anzahl der Datensätze” erhöhen → "alles anzeigen": es werden alle bisherigen Einträge auf einer Seite ausgegeben.
Ortsnamen-Konkordanz
In manchen Fällen erweitern wir das Angebot über die Angaben bei
Lauro hinaus, beispielsweise wenn dort nur eine Abtei oder Kirche
angegeben ist, nicht aber wo diese gelegen ist (zum Beispiel "Stift
Rein").
Damit wir nicht Gefahr laufen, dass Einträge doppelt
erfasst werden, wurden davon betroffene Fälle im Team-Dokument gesammelt
(d.h. neben der oben angeführten Überprüfung muss ergänzend hier ein
Blick hinein geworfen werden, um Redundanzen zu vermeiden).
Vorgehen Phase "Orte und Grabstätten"
- Orte sind in die Tabelle "ort" einzutragen.
- Grabstätten sind in die Tabelle "grabstaette" aufzunehmen; im Feld id_ort ist die ID des zugehörigen Ortes einzutragen3.
- Wir verwenden bei den Bezeichnungen die der Wikipedia, da die von Lauro (aus Platzgründen) nicht immer komplett sind.
- Wiki-Eintrag (falls vorhanden) einbinden via Wikidata Q-ID (Unter Werkzeuge → Wiki-Datenobjekt → Nummer samt Q kopieren und in das entsprechende Feld eintragen.
- Geokoordinaten aus der Wikipedia beziehen: oben rechts im Wiki-Eintrag → unter "Kartendienste ohne Direktlinks" die "Decimal degrees latitude and longitude"-Werte kopieren
Anmerkungen
- Für eine ausführliche Beschreibung der verschiedenen Arten von Joins und ihre Verwendung sei verwiesen auf den entsprechenden Abschnitt im Handbuch: Erlernen einer Datenbanksprache: Structured Query Language (SQL) II #Verknüpfung von Tabellen: Joins.↩︎
- Das Ergebnis zeigt, dass es in der Tabelle Ort einige Orte gibt, die keiner Grabstätte zugewiesen sind, da sie als Geburts- oder Sterbeort, nicht aber als Begräbnisort in Erscheinung treten.↩︎
- Zur Erleichterung der Eintragung werden die entsprechenden Fremdschlüssel aktiviert, d.h. die Eintragung erfolgt durch Anklicken des entsprechenden Namens im Auswahlmenü.↩︎
Joins Vertiefung, Teamorganisation III
Vertiefung SQL-Joins
Zur Vertiefung des Erlernten werden wir im Folgenden eine etwas
komplexere Datenbankabfrage über mehrere Tabellen erarbeiten. Ziel
unserer Beispielabfrage ist es die Grabstätten mit den meisten darin
befindlichen Habsburgern zu ermitteln. Dabei sollen nur Bestattete
berücksichtigt werden, die ausschließlich an einem Ort liegen.
Die Verbindung der Personen mit ihren Grabstätten
erfolgt über die Verknüpfungstabelle "begraben". Zum besseren
Verständnis gehen wir Schritt für Schritt vor.
- Zunächst joinen wir nur die Tabelle "personen" mit der Tabelle
"begraben":
SELECT personen.name, personen.funktion, begraben.id_grabstaette, begraben.bestattungsart, begraben.komplett FROM personen INNER JOIN begraben ON personen.id_person = begraben.id_person;
- Im nächsten Schritt fügen wir in einem zweiten Schritt1 die
Grabstättenbezeichnung hinzu:
SELECT personen.name, personen.funktion, begraben.bestattungsart, begraben.komplett, grabstaette.name, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN grabstaette ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person
- Nun möchten wir noch den Ort der Grabstätte mit einfließen
lassen:
SELECT personen.name, personen.funktion, begraben.bestattungsart, begraben.komplett, grabstaette.name, ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person
- Wie wir in den vorangehenden Einheiten zu SELECT-Abfragen gelernt
haben, können wir die Abfrage nun noch weiter spezifizieren, z.B. durch
eine WHERE-Klausel. Wir möchten uns im Folgenden nur noch diejenigen
Fälle ausgeben lassen, bei denen es sich um eine Körperbestattung (=
"Typ 1") handelt:
SELECT personen.name, personen.funktion, begraben.bestattungsart, begraben.komplett, grabstaette.name, ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1"
- In der nun ausgegebenen Ergebnisliste finden sich aber noch Fälle,
bei denen zwar der Körper begraben wurde, jedoch nicht komplett, d.h.
andere Körperteile (Herz, Eingeweide) liegen andernorts. Filtern wir
diese Fälle nun noch heraus, um nur die Ganzkörperbestattungen zu
erfassen:
SELECT personen.name, personen.funktion, begraben.bestattungsart, begraben.komplett, grabstaette.name, ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1" AND komplett = "1"
Merke: Bei zunehmender Komplexität der Abfrage nimmt die Zahl der Ergebnisse entsprechend ab.
- Im nächsten Schritt möchten wir nun herausfinden, wie viele Personen
in den einzelnen Grabstätten begraben liegen. Hierzu greifen wir auf die
COUNT-Funktion2 zurück und
gruppieren das Ergebnis
nach den Grabstätten:
SELECT personen.name, personen.funktion, begraben.bestattungsart, begraben.komplett, grabstaette.name, COUNT(*) "Anzahl", ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1" AND komplett = "1" GROUP BY grabstaette.name
- Das Ergebnis erscheint noch nicht zufriedenstellend, da wir jeweils
nur den ersten Fall angezeigt bekommen. Daher müssen wir noch eine
weitere Funktion verwenden: GROUP_CONCAT():
SELECT begraben.bestattungsart, begraben.komplett, grabstaette.name, COUNT(*) "Anzahl", GROUP_CONCAT(personen.name, personen.funktion), ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1" AND komplett = "1" GROUP BY grabstaette.name
- Schöner wird es, wenn wir noch ein Leerzeichen samt Komma zwischen
Namen und Titel einfügen; außerdem können wir die GROUP_CONCAT-Spalte
als "Personen" bezeichnen3:
SELECT begraben.bestattungsart, begraben.komplett, grabstaette.name, COUNT(*) "Anzahl", GROUP_CONCAT(personen.name, ', ', personen.funktion SEPARATOR '\n') "Personen", ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1" AND komplett = "1" GROUP BY grabstaette.name
- Zu guter Letzt können wir noch nach der Anzahl sortieren und auch
innerhalb der Spalte "Personen" eine Sortierung einfügen,
sinnvollerweise nach dem Namen der Person:
SELECT begraben.bestattungsart, begraben.komplett, grabstaette.name, COUNT(*) "Anzahl", GROUP_CONCAT(personen.name, ', ', personen.funktion ORDER BY personen.name SEPARATOR '\n') "Personen", ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1" AND komplett = "1" GROUP BY grabstaette.name ORDER BY Anzahl DESC
- Optional können wir noch als Kriterium angeben, dass nur die
Grabstätten ausgegeben werden sollen, bei denen mehr als 3 Personen
begraben liegen (HAVING-Funktion):
SELECT begraben.bestattungsart, begraben.komplett, grabstaette.name, COUNT(*) "Anzahl", GROUP_CONCAT(personen.name, ', ', personen.funktion ORDER BY personen.name SEPARATOR '\n') "Personen", ort.ortsname, grabstaette.geokoordinate1, grabstaette.geokoordinate2 FROM personen INNER JOIN (begraben INNER JOIN (grabstaette INNER JOIN ort ON grabstaette.id_ort = ort.id_ort) ON begraben.id_grabstaette = grabstaette.id_grabstaette) ON personen.id_person = begraben.id_person WHERE bestattungsart = "1" AND komplett = "1" GROUP BY grabstaette.name Having Anzahl > 3 ORDER BY Anzahl DESC
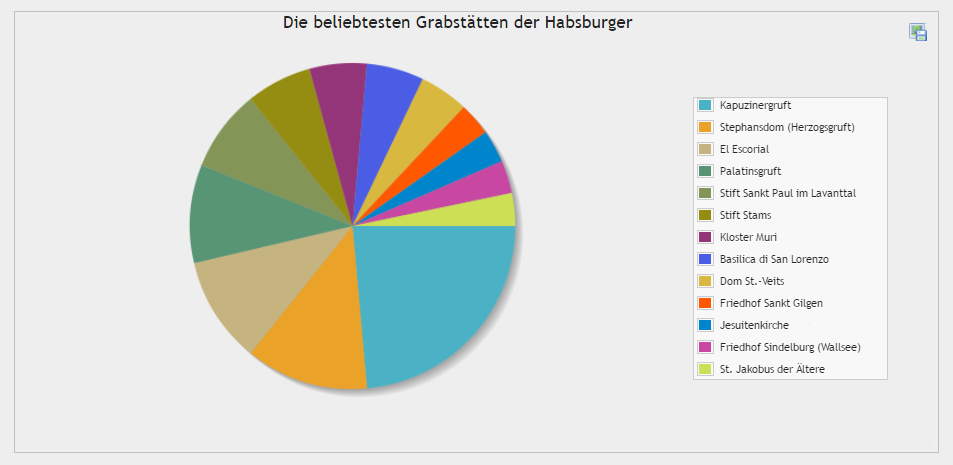
Ergebnisabfrage unmittelbar über die
phpMyAdmin-Oberfläche visualisieren:
- Klicken Sie auf "Diagramm anzeigen"
- Wählen Sie bei x-Achse "name" und bei Reihe "Anzahl" an
- Wählen Sie als Diagrammtyp "Torte" aus
- Vergeben Sie eine Überschrift
- In der rechten oberen Ecke der Darstellung finden Sie die Option, das Diagramm als Bild abzuspeichern
Fortsetzung 2: Datenstrukturierung unseres Mapping-Projekts
Vorgehen Phase "Personen"
- Personen werden in die Tabelle "personen" eingetragen; es werden sowohl die fettgedruckten Namen wie auch die darunter befindlichen Eltern/Ehepartner erfasst (Hier gilt es vorsichtig zu sein, um Redundanzen zu vermeiden!)
- Name wird - sofern korrekt - von Lauro übernommen
- Als Funktion (Titel) greifen wir auf Wikipedia zurück und tragen den jeweils höchsten erreichten Titel ein
- Zeitliche Angaben werden als "unsicher" (1) oder "sicher" (2) gekennzeichnet
- Bei Geburts- und Sterbeort binden wir die Orte aus der entsprechenden Tabelle via Fremdschlüssel ein. Fehlt der entsprechende Ort, so muss er zunächst in der Tabelle "ort" nachgetragen werden
- Metainformationen einbinden: GND-Nummer (via Wikipedia); Kaiserhof-ID4; Wikidata-Seite via Q-Nummer5: Wikipedia-Artikel → Werkzeuge → Wikidata-Datenobjekt → Q-Nummer befindet sich neben dem Namen; gibt es keinen Eintrag bei Wikipedia, kann in die vorgesehene Spalte ("link_alt") eine andere (vertrauenswürdige) Webseite verlinkt werden
- Abbildungen zu den Personen können entweder über die Kaiserhof-ID oder über das Wikidata-Objekt bezogen werden6.
Vorgehen Phase "Verknüpfungstabellen"
- Verknüpfung der Personen mit den Grabstätten in der Tabelle
"begraben"
- Personen und Grabstätten nach den Angaben von Lauro über ihre ID zuordnen
- ENUM-Auswahlfeld "bestattungsart" (1 = Körper; 2 = Herzurne; 3 = Intestinaurne; 4 = unbekannt)
- ENUM-Auswahlfeld "komplett": 1 = ja, 2 = nein (Spezifierung der Körperbestattung)
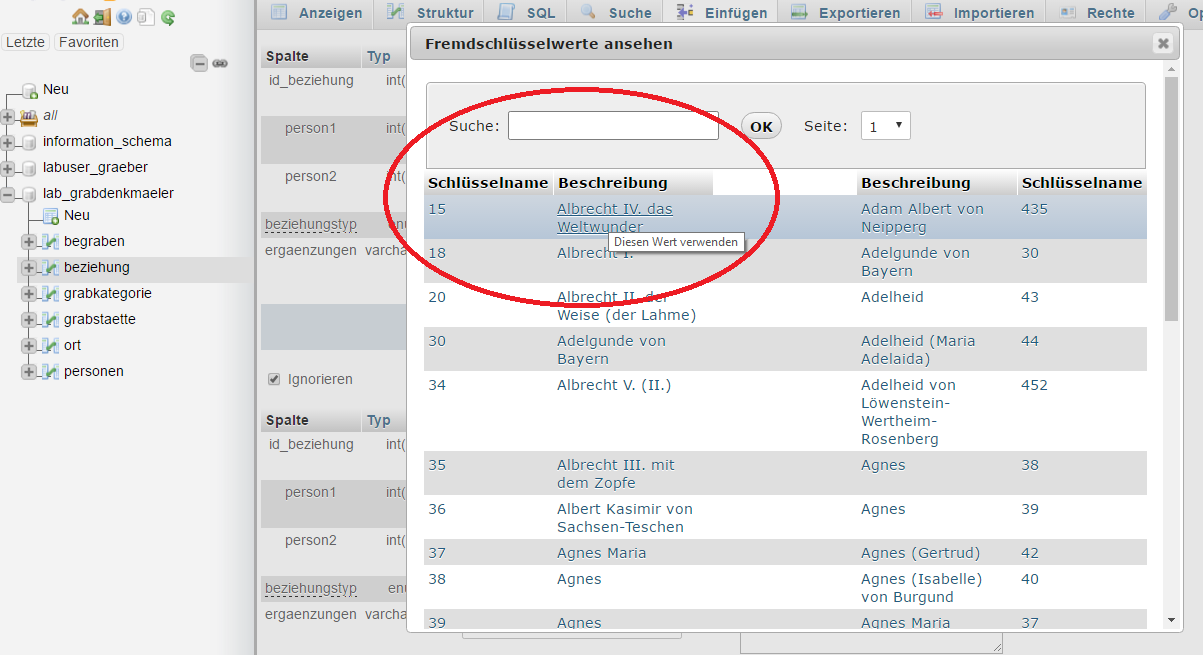
- Verknüpfung der Beziehungen der Personen in der Tabelle "beziehung"
- Personen nach den Angaben von Lauro über ihre ID zuordnen (vgl. Abbildungen)
- Fettgedruckte Person den Eltern zuordnen (ENUM-Auswahlfeld "beziehungstyp": "ist Ehepartner von" (1), "ist Kind von" (2)
- Spalte "ergaenzungen" für Zusatzinformationen (z.B. "zweite Ehefrau von..")
Anmerkungen
- Es können beliebig viele Tabellen miteinander gejoint werden. Berücksichtigt werden müssen dabei die Regeln der Algebra (in sich geschlossene Abfragen, Klammerregeln)↩︎
- Für einen Einstieg in den Einsatz von Funktionen in SQL vgl. den Abschnitt im Handbuch: Erlernen einer Datenbanksprache: Structured Query Language (SQL) II #Funktionen in SQL - eine Auswahl↩︎
- Allgemeiner Hinweis: Sollte der Inhalt der Tabellenfelder nicht komplett angezeigt wird, klicken Sie auf "Optionen" → "Vollständige Texte".↩︎
- Das Kaiserhof-Projekt aufrufen, in der Suchmaske nach "Habsburg" suchen↩︎
- Wikipedia-Verlinkung und verschiedene Sprachausgaben: Die
Q-ID ist die einzige Schnittstelle für alle unterschiedlichen Versionen
eines Artikels in unterschiedlichen Sprachen (allesamt separate Artikel,
keine Sprachausgaben!). Mit Hilfe eines in der ITG entwickelten
Resolvers wird die präferierte Sprache des Nutzers erfasst und der
Wiki-Artikel in dieser - sofern vorhanden - ausgegeben. Ist der Artikel
nicht in dieser Sprache vorhanden, so wird die eingestellte
Standardsprache (Deutsch) ausgegeben. Jeder Wikipedia-Link ist nach
folgendem Schema aufgebaut:
http://wikidata.org/wiki/Special:GoToLinkedPage?site={SPRACHE}wiki&itemid=Q{ID}.↩︎ - es gilt stets darauf zu achten, dass es sich um gemeinfreie Abbildungen handelt, was bei diesen beiden Webangeboten gewährleistet wird.↩︎
Website-Erstellung: Ihr erster Karten-Prototyp
Benötigte Bestandteile
Damit wir die Daten, die wir in den vergangenen Sitzungen strukturiert erfasst haben, in Kartenform visualisieren können, benötigen wir verschiedene Komponenten1:
- Eine HTML-Datei, auf der die Oberfläche der Webseite, also das Front-End basiert
- Eine JavaScript-Datei, die in diese HTML-Seite eingebunden wird, um dynamische Elemente zu generieren (in unserem Fall die Google Map mit verschiedenen Funktionalitäten)
- Eine CSS-Datei, die wir ebenfalls in unsere HTML-Seite einbinden, um das Aussehen der einzelnen Komponenten der HTML-Seite zu gestalten
Hinweis: Selbstverständlich ist es auch möglich, alle
oben genannten Informationen in der HTML-Datei unmittelbar zu vereinen
und auf das Anlegen mehrerer Dateien zu verzichten. Sobald jedoch
bestimmte Elemente nicht nur in einer, sondern in mehreren Seiten
eingebunden werden sollen, ist es sinnvoller, diese einmal an zentraler
Stelle für alle Dateien abzulegen2.
Praktische Vorgehensweise
Auf dem Virtuellen Desktop legt jeder Teilnehmer im Bereich
"Persönlicher Ordner" einen Ordner "habsburg" an; dieser Ordner
simuliert unseren Webspace (normalerweise auf dem Webserver). In diesem
Ordner legen wir zwei Unterordner an, zum einen "css" für Cascading
Stylesheet, zum anderen "js" für JavaScript.
Anschließend öffnen wir einen Editor unserer Wahl (im DHVLab
beispielsweise Kate oder Sublime 2) und erstellen drei neue
Textdateien:
- habsburg.html (wird im Ordner "habsburg" abgelegt)
- style.css (wird im Unterordner "css" abgelegt)
- map.js (wird im Unterordner "js" abgelegt)
Die HTML-Datei
Im Folgenden wenden wir uns der Erstellung der HTML-Datei zu:
<!DOCTYPE html>
<html lang=" de">
<head>
<!-- Das ist unser ein Kommentar, den der
Browser nicht ausgibt-->
<!-- Head-Bereich, enthält
Metainformationen über die Webseite (werden nicht im Browser ausgegeben) -->
<title>Habsburger Grabdenkmäler</title>
<!-- Seitentitel, im Browserfenster, Leesezeichen, Suchmaschinen -->
<meta charset="utf-8">
<!-- Mit utf-8 können Sonderzeichen direkt genutzt werden (im Deutschen z.B.
Umlaute ö, ä, ü) -->
<link rel="stylesheet" type="text/css" href="css/style.css">
<!-- Datei style.css mit Informationen zur Gestaltung unserer HTML-Seite -
befindet sich im Ordner css -->
<script type="text/javascript"
src="http://maps.googleapis.com/maps/api/js?v=3.exp"></script>
<!-- Einbinden der Google Maps API -->
<script type="text/javascript" src="js/map.js"></script>
<!--
Einbinden unserer JavaScript-Datei, die die Funktionen zu unserer Karte enthalten
wird. -->
</head>
<body>
<!-- Umfasst den Inhalt, der im Browser ausgegeben wird -->
<h1>Die Grabstätten der Habsburger</h1>
<h2>Ein Datenbankprojekt des Hauptseminars, WiSe 2016/17</h2>
<!-- Überschriften vom Typ 1 und 2 -->
<div id="canvas"></div>
<!-- Das Google-Maps Layer wird mit einem div-Container eingebunden -->
<p align="center"> Ich bin ein Textblock mit einem
/> Zeilenumbruch
darin. Außerdem findet sich hier ein Link auf unsere <b>'echte'</b>
<a
href="http://www.habsburg.gwi.uni-muenchen.de/">Habsburg-Projektseite</a>.
Wenn wir möchten, dass sich der Link in einem neuen Fenster öffnet,
fügen wir noch das Attribut <i>target="blank"</i> hinzu: Wir verlinken
also auf erneut auf die <a target="blank"
href="http://www.habsburg.gwi.uni-muenchen.de/">Habsburg-Projektseite.</a></p>
<button onmousedown="init(); marker();">Marker</button>
<button onmousedown="line();">Linie</button>
<!-- Es werden zwei Schaltflächen erstellt, die unterschiedliche
Funktionalitäten besitzen. Bei Klick auf die erste Schaltfläche werden
die Marker gesetzt, bei der zweiten eine Verbindungslinie zwischen den
Markern gezogen. Ihre Funktionalität erhalten sie über
JavaScript-Funktionen, zu denen wir weiter unten kommen
werden.-->
</body>
Die CSS-Datei
Nun bearbeiten wir die erstellte CSS-Datei im Editor, um ausgewählten
Bereichen in unserer HTML-Datei Gestaltungsmerkmale zu übergeben. Wir
beschränken uns dabei auf einige wenige Merkmale:
html, body {
height: 100%;
margin: 0px;
padding: 0px;
}
#canvas {
width: 90%;
height: 80%;
margin: auto;
}
/* Ein Kommentar in CSS */
/* canvas ist
der Bereich für den Google Maps Layer. Das Doppelkreuz signalisiert,
dass es sich hier um ein bestimtes div-Element mit der ID "canvas"
handelt. */
h1 {
text-align: center;
}
h2 {
text-align: center;
color: green;
}
Die JavaScript-Datei
Beispiel 1
In diesem ersten Beispiel werden wir eine Karte erstellen, auf der
sich mehrere, verschiedenfarbige Marker befinden und diese mit einer
Linie verbinden. Sowohl die Marker als auch die Linien sollen nur dann
erscheinen, wenn der Benutzer auf den zugehörigen Button klickt.
onload = init;
//mit dem Laden der Seite soll das Initialisieren der Karte einhergehen.
var map, mapOptions
var muenchen = new google.maps.LatLng(48.149600, 11.574481)
var paris = new google.maps.LatLng(48.859836, 2.359529)
var frankfurt = new google.maps.LatLng(50.110556, 8.682222)
var m1, m2, m3
// Variablen können nebeneinander, durch Kommata getrennt, geschrieben werden.
// Wir weisen den geographischen Längen- und Breitenangaben Variablennamen zu
(muenchen, paris, frankfurt)
// m1, m2, m3 sind Variablen, die wir als Marker unten zu diesen Geodaten einsetzen
werden
// Zunächst einmal muss die Google Maps initalisiert werden.
function init() {
map = new google.maps.Map(
// Der Variable map wird die JavaScript-Klasse google.maps.Map zugewiesen.
// Wir legen eine neue Instanz dieser Klasse mithilfe des JavaScript-Operators new
an.
document.getElementById("canvas"),
// Referenz zum JavaScript-Objekt document.
mapOptions = {
//
Nun definieren wir mit der Variable mapOptions das Aussehen unserer Karte; es sind
kaum Grenzen gesetzt.
center: new google.maps.LatLng(48.149600, 11.574481),
zoom: 7,
streetViewControl:false,
scaleControl: true,
mapTypeControl:true,
mapTypeControlOptions: {
style: google.maps.MapTypeControlStyle.HORIZONTAL_BAR,
position: google.maps.ControlPosition.BOTTOM_CENTER
},
zoomControl:true,
zoomControlOptions: {
position: google.maps.ControlPosition.RIGHT_BOTTOM
},
mapTypeId: google.maps.MapTypeId.TERRAIN
}
);
}
// die verwendeten Optionen finden sich allesamt in der offiziellen Google Maps
API-Beschreibung:
// https://developers.google.com/maps/documentation/javascript/tutorial?hl=de
// Probiert die unterschiedlichen Möglichkeiten aus, indem ihr false durch true
ersetzt, andere Koordinaten einsetzt, eine andere Zoomstufe oder die in KAPITÄLCHEN
gesetzten Style-Informationen verändert.
function marker() {
// Eine weitere Funktion, die dem Setzen von Markern gilt.
m1 = new google.maps.Marker(
{ map: map, position: muenchen, animation: google.maps.Animation.DROP, icon:
"http://maps.google.com/mapfiles/ms/icons/blue-dot.png"
});
// Wir weisen der oben definierten Variable m1 die JavaScript-Klasse
google.maps.Marker zu.
// In geschweiften Klammern finden sich Anweisungen, was das Programm erledigen
soll:
// "Verwende die Karte "map", setze den Marker an die Position "muenchen" (also die
eingangs definierte Variable mit den Geokoordinaten). "Wende die Animation "Drop"
an, verwende ein blaues Icon. Die Standardfarbe ist rot -> siehe Frankfurt.
m2 = new google.maps.Marker(
{ map: map,
position: paris, animation: google.maps.Animation.DROP, icon:
"http://maps.google.com/mapfiles/ms/icons/green-dot.png"
});
m3 = new google.maps.Marker(
{ map: map, position: frankfurt, animation: google.maps.Animation.DROP
});
} function line() {
// Es gibt viele weitere Möglichkeiten der Visualisierung, z.B. die Verbindung
einzelner Marker mit Linien.
new google.maps.Polyline(
{
map: map, path: [muenchen, frankfurt, paris], geodesic: true
})
}
// wir binden diese Funktion über einen Button in die HTML-Datei ein.
Beispiel 2
Im folgenden wählen wir einen leicht veränderten Ansatz. Wir nehmen
an, dass durch ein vorgeschaltetes PHP-Skript Datensätze aus unserer
Datenbank in die JS-Datei in Form eines Arrays eingespeist wurden. Auf
diese Informationen wird im Anschluss dynamisch zugegriffen:
onload = init;
var map, mapOptions
var marker = []
var p = [
['Adelgunde von Bayern','Herzogin von
Modena','w','1823','1914','61234',48.205673,16.370173],
['Adelheid (Maria Adelaida)','Königin von
Sardinien','w','1855','231856',45.080833,7.767500]
];
// Vorteil: der komplette DB-Bestand wird zunächst abgerufen und in die Karte
eingebunden; dadurch sind alle eingebundenen Funktionen (z.B. eine Timeline) nach
einmaligem Laden durch den Benutzer auch offline benutzbar.
// Zunächst einmal muss die Google Maps initialisiert werden.
function init() {
map = new google.maps.Map(
// Der Variable map wird die JavaScript-Klasse google.maps.Map zugewiesen.
// Wir legen eine neue Instanz dieser Klasse mithilfe des JavaScript-Operators new
an.
document.getElementById("canvas"),
// Referenz zum JavaScript-Objekt document.
mapOptions = {
// Nun definieren wir mit der Variable mapOptions das Aussehen unserer Karte; es
sind kaum Grenzen gesetzt.
center: new google.maps.LatLng(48.149600, 11.574481),
zoom: 7,
streetViewControl:false,
scaleControl: true,
mapTypeControl:true,
mapTypeControlOptions: {
style: google.maps.MapTypeControlStyle.HORIZONTAL_BAR,
position: google.maps.ControlPosition.BOTTOM_CENTER
},
zoomControl:true,
zoomControlOptions: {
position: google.maps.ControlPosition.RIGHT_BOTTOM
},
mapTypeId: google.maps.MapTypeId.TERRAIN
}
);
for (var i in p){
marker[i] = new google.maps.Marker(
{map: map, position: new google.maps.LatLng(p[i][6], p[i][7]), opacity: 0.66, title:
p[i][0], id:i, label: '*'});
}
// For-Schleife wiederholt die Anweisung, solange die Bedingung (var i in p
vorhanden) zutrifft. Der nachfolgende Anweisungsblock wird beim Durchlauf
ausgeführt, in unserem Fall 2x.
// Bei den einzelnen Parametern wird jeweils die Position der Information im Array
angegeben (z.B. p[i][0] = Name der Person). Label fügt dem Marker ein Symbol
hinzu.
}
Anmerkungen
- Der Bezug der Daten aus der DB erfolgt über ein PHP-Skript. Die Daten werden unmittelbar in die JavaScript-Datei importiert; das hat den Vorteil, dass die Karte lokal mit allen Funktionalitäten abgerufen werden kann, nachdem die Daten einmal importiert wurden. Die PHP-Datei wurde im Kursrahmen nicht selbst erstellt, sondern von der ITG bereit gestellt.↩︎
- Dieses Vorgehen ist Ihnen bereits aus der Normalisierung von Forschungsdaten in relationalen DB-Systemen bekannt.↩︎