Einführung in die Arbeit mit Datenbanken
Einführung Datenbanken
Im vorangehenden Manual haben wir uns mit dem Tabellenkalkulationsprogramm Calc vertraut gemacht. Dieses eignet sich für die Verwaltung und Verarbeitung (kleinerer) Datensammlungen. Die grafische Benutzeroberfläche ermöglicht eine benutzerfreundliche Bearbeitung. Zeilen und Spalten können grafisch beliebig formatiert werden. Für die Sammlung größerer Forschungsdatenmengen sollte die Verwendung einer (relationalen) Datenbank in Betracht gezogen werden. Diese bietet Ihnen eine Reihe an Vorteilen hinsichtlich Datenstrukturierung, -verwaltung und -analyse1:
- Unabhängigkeit der Daten: In einer Datenbank abgelegte Datensammlungen können in verschiedenen Formaten exportiert und damit universal weiterverarbeitet werden = größtmögliche Kompatibilität
- Leistungsfähigkeit: eine SQL-Datenbank ist idR schneller und leistungsfähiger als native XML-Datenbanken wie eXist oder Tamino
- Schnittstelle zu Programmiersprachen wie JavaScript (via AJAX), PHP oder Python. Ihre Kombination bildet die Grundlage für die Schaffung komplexer dynamischer Webinterfaces.
- Vermeidung von Redundanz: In einer (normalisierten) Datenbank werden Daten einheitlich und eindeutig identifizierbar abgelegt.
- Verknüpfbarkeit der Daten durch die (automatische) Zuweisung von Schlüsseln (ID's)
- Parallele Bearbeitung durch mehrere Mitarbeiter möglich.
- Durchsuchbarkeit und Möglichkeit zu umfassenden Berechnungen auf Grundlage der Daten
Im folgenden Manual werden wir uns zunächst die theoretischen Grundlagen (Datenmodelle, relationale Algebra) aneignen und dabei einen Schwerpunkt auf das relationale Datenmodell legen. Anschließend werden wir uns dem relationalen Datenbanksystem2 zuwenden und schließlich mit Hilfe eines relationalen Datenbankmanagementsystems3 in die praktische Arbeit einsteigen. Hierzu werden wir uns mit der webbasierten, grafischen Benutzeroberfläche phpMyAdmin vertraut machen und die Datenmanipulationssprache SQL anhand praktischer Beispiele (Abfrage von Daten, Manipulation von Daten, Änderungen der Datenbankstruktur) erlernen.
Um Ihnen den Nutzen der Arbeit mit Datenbanken gleich zu Beginn zu
illustrieren, sei an dieser Stelle auf eine Auswahl an Projekten
der IT-Gruppe Geisteswissenschaften verwiesen, die auf MySQL-Datenbanken
zurückgreifen. Ihnen gemein ist, dass sich das Framework beliebig
verändern lässt, ohne dabei mit den Daten in Kontakt zu kommen. Wichtig
ist immer, dass die Daten sauber strukturiert abgelegt
wurden. Dann ist ihre Verwendung in verschiedensten Szenarien
denkbar:
Biblia Hebraica
Transcripta
Höflinge der
Habsburgischen Kaiser
VerbaAlpina
Referenzen und Hinweise
Empfehlenswerte Client-Programme für MySQL-Datenbanken:
- MySQL
Workbench -
Arbeitsumgebung zur Erstellung, Modellierung und Bearbeitung von
MySQL-Datenbanken.
- HeidiSQL - Ein weiteres Datenbankmanagementsystem für MySQL-Datenbanken.
Weiterführende Links
- Mindestanforderungen an eine relationale Datenbank und die zwölf goldenen Regeln der Relationalität: Mindestanforderungen und zwölf Regeln
- Grundlegendes zu Relationalen Datenbanken
- Datenmodellierung und relationale Datenbanken, Stephan Lücke
- zum Erlernen und Üben von SQL: amazing-sql.com
- SQL Tutorial der W3Schools (Englisch)
- Sololearn-App: SQL-Kurs
- Einführung, Grundlegendes (LUIS, Universität Hannover)
- Datenmodellierung mit SQL (LUIS, Universität Hannover)
- Informationen filtern (LUIS, Universität Hannover)
- Tabellenbeziehungen abbilden (Joins) (LUIS, Universität Hannover)
- Daten berechnen (LUIS, Universität Hannover)
- Wichtige SQL-Befehle (Delete, Insert, Update) (LUIS, Universität Hannover)
Anmerkungen
- Zum Erstellen von Grafiken und Visualisierungen ist eine SQL-Datenbank nur eingeschränkt verwendbar. Die Visualisierung sollte durch Export der Forschungsdaten in hierfür geeignete Software erfolgen.↩︎
- In unserem Fall greifen wir auf das sehr leistungsstarke Datenbanksystem MySQL zurück. Daneben existieren weitere kommerzielle und freie Datenbanksysteme wie Oracle, Microsoft SQL Server, PostgreSQL etc.↩︎
- Die OpenSource-Software phpMyAdmin zählt mit rund 50 Millionen Installationen weltweit zu den am meisten verbreiteten Datenbankverwaltungssystemen.↩︎
Verschiedene Arten von Datenmodellen
Mit Hilfe eines Datenmodells1 werden die zu beschreibenden und zu verarbeitenden Daten eines bestimmten (Forschungs-)Bereiches modellhaft mit ihren Beziehungen zueinander dargestellt. Es dient in der konzeptionellen Phase eines Datenbankprojekts als Grundlage zur Erstellung des Datenbank-Designs. Zwei Fragen stehen bei der Erstellung eines Datenmodells im Fokus:
- Welche Objekte stehen im Erkenntnisinteresse und welche Beziehungen zwischen diesen Objekten besitzen Relevanz?
- Auf welche Weise sollen die Objekte und ihre Beziehungen dargestellt werden?
Ein Datenmodell gibt Antworten auf diese Fragen. Als theoretische Grundlage eines Datenbanksystems beschreibt ein Datenmodell, auf welche Weise Daten in einem Datenbanksystem abgespeichert und verarbeitet werden sollen. Ein Datenmodell besitzt im Gegensatz zu einem Datenbankmodell (Stichwort: Datenbankschema; siehe unten) nicht zwangsläufig einen konkreten technischen Bezug und ist damit abstrakter.
Grundsätzlich gilt bei der Modellierung von Daten:
- Strukturierung durch Kategorisierung, d.h. einzelne Objekte werden übergeordneten Kategorien (Objektklassen/Entitäten) zugeordnet. Zunächst gilt es also die einzelnen Objekte (Instanzen der Entitäten) zu bestimmen. Objekte besitzen Beziehungen zu anderen Objekten. Objekte können beliebig viele Eigenschaften (Attribute) besitzen.
- Die Modellierung ist abhängig vom Forschungsinteresse des/der Wissenschaftlers/-in, d.h. verschiedene Ansätze sind möglich.
Eine Auswahl wichtiger Arten von Datenmodellen2:
- Listenformat/Liste (RIS)
- Hierarchisches Datenmodell (XML)
- Netzwerk-Datenmodell
- Objektorientiertes Datenmodell
- Relationales Datenmodell
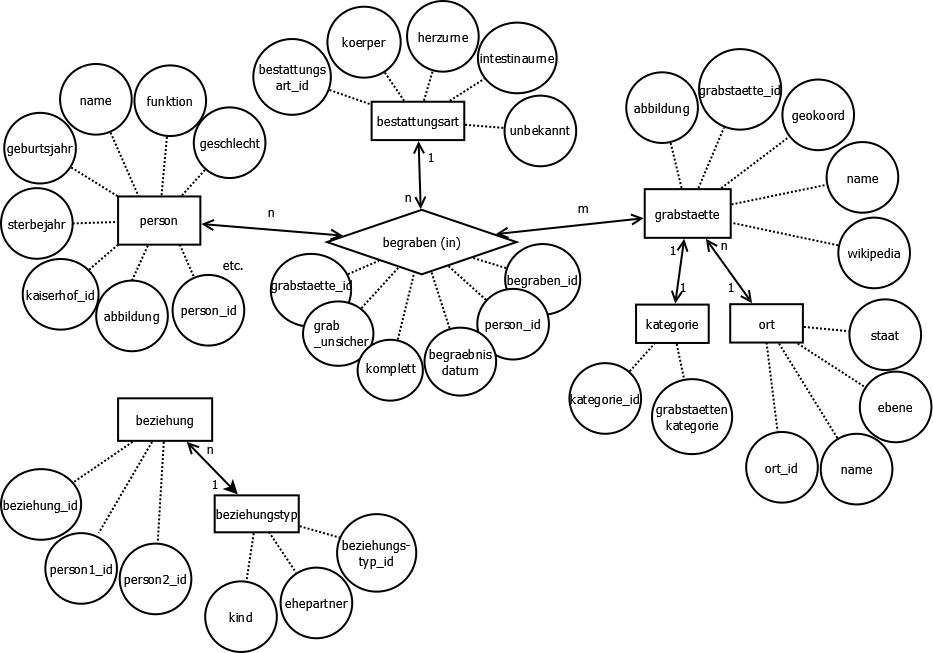
Als de-facto-Standard bei der Datenmodellierung gilt das Entity Relationship Modell, kurz ERM. Die Objekte werden als "Entitäten", ihre Beziehung untereinander als "Relationen" bezeichnet. Objekte können unterschiedliche Arten von Beziehung zueinander besitzen:
- 1:1-Beziehungen: Jedem Datensatz aus einer Tabelle A ist
genau ein Datensatz aus einer Tabelle B zugeordnet und umgekehrt.
Diese Art von Beziehung tritt eher selten auf.
Beispiel: Jede Urkunde besitzt genau eine Registraturnummer. Umgekehrt ist
jede Nummer genau einer Urkunde zugeordnet.
- 1:n-Beziehungen: Jedem Datensatz aus einer Tabelle A können
beliebig viele passende Datensätze aus einer Tabelle B zugeordnet
werden, jedoch umgekehrt nur ein Datensatz aus Tabelle B einem Datensatz aus
Tabelle A. Diese Form der Beziehung tritt am häufigsten auf.
Beispiel: Einer Partei können beliebig viele Politiker angehören. Umgekehrt
kann jeder Politiker nur einer Partei angehören.
- n:m-Beziehungen: Jedem Datensatz aus einer Tabelle A können
beliebig viele passende Datensätze aus einer Tabelle B zugeordnet
werden und umgekehrt. Dies erfolgt über eine dritte, zu erstellende
Tabelle, in der zur eindeutigen Zuordnung die Primärschlüssel der jeweiligen
Datensätze in Verbindung gesetzt werden.
Beispiel: Ein Buch kann beliebig viele Autoren besitzen und jeder Autor kann
beliebig viele Bücher verfasst haben.
Sowohl Objekte als auch die Beziehung zwischen Objekten können
Eigenschaften (Attribute) aufweisen,
die diese genauer beschreiben. Üblicherweise werden in einem ERM die
Entitäten rechteckig, die Relationen
rautenförmig dargestellt.
Grundlegende Komponenten des ERM sind also Entitäten, Relationen und
Attribute. Ihre grafische, relationale Darstellung wird als
Entity-Relationship-Diagramm''
(ERD'') bezeichnet.
Nachfolgend ein Beispiel (Abb. 1) eines ERD aus dem Kurs "Vom
gedruckten Buch zur digitalen Karte":
Anmerkungen
- Grundlage für die folgenden Ausführungen: Institut für Informatik und DH-Lehre.↩︎
- Vgl. hierzu die Beispiele im Handbuch von Stephan Lücke auf dh-lehre.↩︎
Das relationale Datenmodell - Theoretische Grundlagen I
Das relationale Datenmodell organisiert
Informationen in Gestalt von einer oder mehrerer
Tabellen. Die Bezeichnung rührt daher, dass Tabellen in
der Fachsprache auch als "Relationen" bezeichnet werden.
Prinzipiell gilt: Alle Arten von Information können auf
Tabellen heruntergebrochen werden.
Tabellen bestehen aus Zeilen und Spalten:
- Spalten (auch Attribute, Felder, Eigenschaften
genannt):
- Die Spaltennamen (über der jeweiligen Spalte befindlich) werden als Attribute bezeichnet.
- Den einzelnen Spalten wird jeweils ein bestimmter Datentyp zugeordnet.
- Spalten unterscheiden sich strukturell, d.h. durch den Datentyp und die Anzahl der möglichen Zeichen.
- Zeilen (auch Tupel genannt):
- Jeder Datensatz (record) stellt eine Zeile in der Tabelle dar.
- Ein Datensatz setzt sich aus den einzelnen Attributwerten der jeweiligen Zeile zusammen.
- Die Anzahl der Attributwerte wird durch das zugrunde liegende relationale Modell festgelegt.
Die Definition von Spalten und Zeilen erfolgt durch eindeutige
Zeichen, sogenannte "Separatoren", z.B. werden Zeilen durch einen
Zeilenumbruch (\n) getrennt, Spalten durch einen Tab(ulator) oder ein
Semikolon (;).
Bestehende Tabellen sind prinzipiell endlos fortführbar, d.h. es können
jederzeit beliebig viele neue Spalten oder Zeilen ergänzt
werden. Die Reihenfolge der Spalten ist nicht relevant. Da sich
die Spalten- oder Attributnamen unterscheiden müssen, kann es nicht zu
einer Doppelung kommen.
Mehrere Tabellen in Relation setzen: Normalisierung und der Einsatz von Schlüsseln
Ein Grundsatz des relationalen Datenmodells ist die Normalisierung: Grundsätzlich gilt es, Redundanzen zu vermeiden, d.h. Informationen sollten möglichst nicht wiederkehrend sondern an zentraler Stelle einmalig abgespeichert werden. Dadurch wird...:
- ...sichergestellt, dass die Konsistenz der Daten erhalten bleibt; d.h. eine Änderung am Datenbestand muss nur einmalig durchgeführt werden. Bereits ein kleiner Tippfehler würde bei redundanten Daten zu erheblichem Korrekturbedarf führen - was wiederum eine potentielle Fehlerquelle darstellt.
- ...vermieden, dass Datensammlungen unnötig aufgebläht werden, wodurch Speicherplatz gespart wird.
Um diesem Grundsatz zu entsprechen, empfiehlt es sich, Informationen
auf möglichst viele Tabellen aufzuteilen, d.h. die
Daten möglichst umfassend zu normalisieren. Vgl. hierzu
das Beispiel "Bibliographische Angaben in relationaler Form angeben" auf
DH-Lehre1.
Dadurch das die Informationen in eigens angelegten Tabellen
abgespeichert werden, können sie, über "eine dritte
Tabelle", miteinander in Verbindung gesetzt
werden. Die Verknüpfung zweier oder mehrerer Tabellen bzw. ihrer
Datensätze erfolgt über sogenannte "Schlüssel"
(ID's), die den Datensatz eindeutig
identifizierbar machen. Jeder Datensatz verfügt über ein
solches eindeutiges Feld zur Identifikation.
Beispiel:
Die Verbindung von Autoren mit den ihnen zugehörigen Buchtiteln
erfolgt über eine eigene Tabelle, in der die jeweilige Autoren-ID mit der oder den
entsprechenden Buch-ID(s) in Verbindung gesetzt wird. Haben zwei Autoren gemeinsam
ein Buch veröffentlicht, so würde jedem Autor (autor1, autor2)
bzw. seiner Autoren-ID die Buch-ID zugeordnet. Wird bei einem Autorennamen ein
Tippfehler festgestellt, so kann dieser in der Autorentabelle verbessert werden. Auf
die Verknüpfung der Autoren-ID mit der Buch-ID hat dies keine Auswirkung.
Je konsequenter der Datenbestand normalisiert wurde, desto schwieriger wird seine Durchdringung durch Benutzer ohne Fachkenntnisse. Daher ist das grundlegende Verständnis des relationalen Datenmodells wichtig. Sie werden in der Praxis immer wieder Verknüpfungstabellen begegnen, die nur aus miteinander in Verbindung gesetzten Schlüsseln (meist Zahlen2) bestehen. Wenn mehrere Schlüssel in einer Tabelle vorhanden sind, wird unterschieden in
- Primärschlüssel (SQL: primary key): Der Primärschlüssel wird den einzelnen Zeilen zur Identifikation zugeteilt. Pro Tabelle gibt es nur einen Primärschlüssel, jede Zeile besitzt demnach nur einen 'unique key. Dieser muss einen Wert besitzen und kann nichtNULL'' sein.
- Fremdschlüssel (SQL: foreign key): Als Fremdschlüssel werden alle anderen, in der Tabelle befindlichen Schlüssel bezeichnet, die auf Primärschlüssel anderer Tabellen verweisen.
Sind Tabellen mit ihren Zeilen und Spalten zunächst zweidimensional, erlangen sie durch die Verknüpfung mit anderen Tabellen Dreidimensionalität.
Datenmodellierung: Gedanken aus der wissenschaftlichen Praxis
- Die Datenmodellierung birgt aus inhaltlicher Sicht den Vorteil, dass man sich mit allen Problemfällen auseinandersetzen muss.
Beispiel Jahreszahl: Prinzipiell verfügt eine Jahreszahl über vier Ziffern (1999). Nun werden unsichere Jahreszahlen jedoch üblicherweise mit mit eckigen Klammern gekennzeichnet (19[99]). Dies gilt es bei der der Modellierung der entsprechenden Spalte der Datenbank zu berücksichtigen. Seien Sie unbesorgt: Es gibt im relationalen Modell für jeden Fall eine Lösung.
- Transparenz der Daten: Dadurch, dass für jeden Fall Kriterien erdacht werden müssen, ist der Wissenschaftler/die Wissenschaftlerin zum Treffen verbindlicher Entscheidungen angehalten ("circa"-Angaben, Zusätze wie "vermutlich" etc. sind in einer relationalen Datenbank nur schwerlich abbildbar). Dies kann hinsichtlich wissenschaftlicher Theoriebildung von Vorteil sein.
- "Viele Wege führen nach Rom": Es gibt nie die eine ausschließliche Lösung. Die vorhandenen Informationen können und sollten stets nach eigenem Ermessen sinnvoll aufgeschlüsselt werden.
- Ein guter Ansatzpunkt um festzustellen, an welcher Stelle ein weiteres Aufsplitten von Informationen sinnvoll sein könnte, ist das Sortieren nach bestimmten Informationen.
Beispiel Autorennamen: Bei der Sortierung nach dem Autorennamen würde Ihnen rasch auffallen, dass das Aufteilen der Autoren in zwei Spalten (autor 1, autor 2) sinnvoll wäre, da sie sonst nie nach dem zweitgenannten Autorennamen sortieren könnten.
Anmerkungen
- Praxisbeispiel auf DH-Lehre↩︎
- Egal, ob sich der Schlüssel aus Zahlen (Standard) oder anderen Zeichen zusammensetzt- es gilt stets das Prinzip der Minimalität: Der Schüssel darf keine überflüssigen Zeichen enthalten, nur solche, die zu seiner Eindeutigkeit beitragen!↩︎
Das relationale Datenmodell - Theoretische Grundlagen II
Die relationale Datenbank in der Praxis
Bei einer Datenbank wird generell unterschieden in
- das Datenbankschema (technische Ausgestaltung des theoretischen Datenmodells) und den
- Datenbank-Zustand (tatsächliche Ausprägung der Datenbank).
Das Datenbankschema beschreibt, aufbauend auf dem Datenmodell die
möglichen Inhalte einer Datenbank sowie die
Struktur/Typen der einzelnen Tabellen und deren
Spalten. Veränderungen am Datenbankschema sind
jederzeit möglich ("Schema-Evolution").
Der Datenbank-Zustand ergibt sich aus dem tatsächlich in der
Datenbank befindlichen Inhalt, sprich der zugewiesenen
Attributwerte. Im Datenbanksystem
(DBS) werden Datenbank-Schema und Datenbank-Zustand
gleichermaßen gespeichert. Ihre Übereinstimmung wird durch das
eingesetzte Datenbankmanagementsystem (DBMS)
kontrolliert.
Beispiel: Das Datenbank-Schema gibt für eine
Spalte vor, dass maximal 10 Zeichen eingetragen werden können. In dieser
Spalte können sich nun Einträge unterschiedlicher Länge (variabel!),
aber nur bis zu zehn Zeichen befinden (Datenbank-Zustand).
Das relationale Datenmodell kommt in relationalen Datenbanksystemen zum Einsatz. Ein Datenbanksystem besteht aus zwei Komponenten: Während (1.) die Datenbank die eigentlichen (Forschungs-)Daten vorhält, können (2.) diese über ein sogenanntes (relationales) Datenbankmanagementsystem verwaltet und verarbeitet werden. Ein Datenbanksystem besitzt die Aufgabe, große Datenmengen
- zu beschreiben
- langfristig abzuspeichern
- im Falle eines Verlusts wieder herzustellen.
Dadurch wird ihre dauerhafte Nutzung durch Client-Programme gewährleistet.
Datenbankmanagementsystem MySQL
Ein Datenbankmanagementsystem, das sowohl auf Servern als auch auf Clients installiert werden kann, ist MySQL. Es gibt im Wesentlichen folgende Zugriffsmöglichkeiten:
- Kommandozeile (Shell)
- Clientprogramm (z.B. HeidiSQL (nur für Windows)
- phpMyAdmin, eine freie Webanwendung zur Verwaltung von MySQL-Datenbanken
SQL: Relationale Algebra als theoretische Grundlage
Zur Abfrage, Manipulation und
Erweiterung der Datenbasis kommt die
Structured Query Language - kurz
SQL - zum Einsatz. Es handelt sich um eine
ISO-codierte, von ihrer Syntax her gesehen relativ einfach aufgebaute
Datenbanksprache, welche semantisch an die englische
Umgangssprache angelehnt ist. Mit dieser deklarativen Datenbanksprache
können unterschiedlichste Abfragen und Operationen
durchgeführt werden. Ihnen allen gemein ist die relationale
Algebra, die ihr theoretisches Fundament darstellt. Diese gibt
vor, in welcher Art und Weise Daten gespeichert, abgefragt/gefiltert,
verknüpft oder verändert werden können. Die Operationen der relationalen
Algebra werden mittels SQL als Datenbankoperatoren
eingebunden bzw. umgekehrt formuliert: die durch eine SQL-Eingabe
angeforderte Datenbankoperation wird durch das DBMS in relationale
Algebra übersetzt.
Die wesentlichen Operationen (aus denen wiederum andere
abgeleitet werden können) sind:
- Selektion (Auswahl von Datensätzen, d.h. Zeilen)
- Projektion (Auswahl von Attributen, d.h. Spalten)
- Kreuzprodukt (Kartesisches Produkt)
- Vereinigung/Join (Horizontale Verknüpfung von Tabellen)
- Union (Vertikale Verknüpfung von Tabellen)
Das Ergebnis einer Abfrage oder Operation ist
immer eine (neue) Tabelle (zunächst
ohne eigenen Namen, solange sie nicht dezidiert abgespeichert
wurde).
Wir werden uns später bei der praktischen Arbeit mit der Datenbank
intensiv mit SQL und ihren Spezifika auseinandersetzen. An dieser Stelle
wollen wir es bei diesen theoretischen Grundzügen belassen. Eine
umfassende Einführung in die relationale Algebra und ihre Bedeutung für
SQL bieten:
IfI
LMU
Wikipedia
Im Folgenden wird zunächst kurz eine Alternative zu phpMyAdmin vorgestellt, MySQL
Workbench.
Anschließend werden wir uns anhand der
phpMyAdmin-Umgebung der Arbeit mit relationalen
Datenbanken annähern und ihre vielfältigen Einsatzmöglichkeiten in der
geisteswissenschaftlichen Forschung verstehen lernen.
MySQL Workbench
Anlegen einer neuen Datenbank
MySQL-Workbench MySQL Workbench ist ein weit verbreitetes Client-Programm zur Verwaltung relationaler Datenbanken (nicht nur MySQL). Es kann alternativ zum Datenbankmanagementsystem phpMyAdmin verwendet werden und ist auf dem Virtuellen Desktop installiert. ⇒ Einen guten Einstieg in die Arbeit mit MySQL Workbench bietet folgendes YouTube-Tutorial ⇒ Bevor Sie beginnen, mit MySQL Workbench zu arbeiten, sollten Sie sich mit den grundlegenden Eigenschaften (relationaler) Datenbanken vertraut machen.
- Öffnen Sie MySQL Workbench (Suche → "Workbench"; Tipp: durch Ziehen des Icons können Sie eine Verknüpfung auf dem Desktop anlegen)
- Im unteren Bereich der Startoberfläche von MySQL Workbench befindet sich der Bereich "Models". Um ein neues Modell anzulegen klicken Sie auf das Plus-Symbol.
- Es öffnet sich ein neues Kontextmenü, in dem sich eine neue Datenbank ("mydb") befindet
- Um den Namen der Datenbank zu ändern, doppelklicken Sie auf das angezeigte Fenster unter "Physical Schemas". Ein neues Fenster öffnet sich, in dem Sie einen neuen Namen, aber auch eine andere Kollationierung wählen können. Schließen Sie das Fenster anschließend einfach über das Icon "Schließen" (weißes Kreuz auf rotem Grund)
- Im Folgenden können Sie in Ihrer Datenbank nach Belieben neue Tabellen hinzufügen (Doppelklick auf "Add Table")
- Für jede Tabelle können Sie im angezeigten Fenster unter den verschiedenen Reitern Änderungen vornehmen (Table: Tabellenname und Kollationierung, Colums: neue Spalten hinzufügen und benennen, Datentypen und Attribute auswählen, z.B. PC = Primary Key, NN = Not Null, UQ = Unique, AI = Auto Increment)
- Möchten Sie mehrere Tabellen miteinander in Beziehung setzen, so können Sie via Tab "Foreign Keys" entsprechende Fremdschlüsselverknüpfungen definieren
Verbindung zu einer bestehenden Datenbank
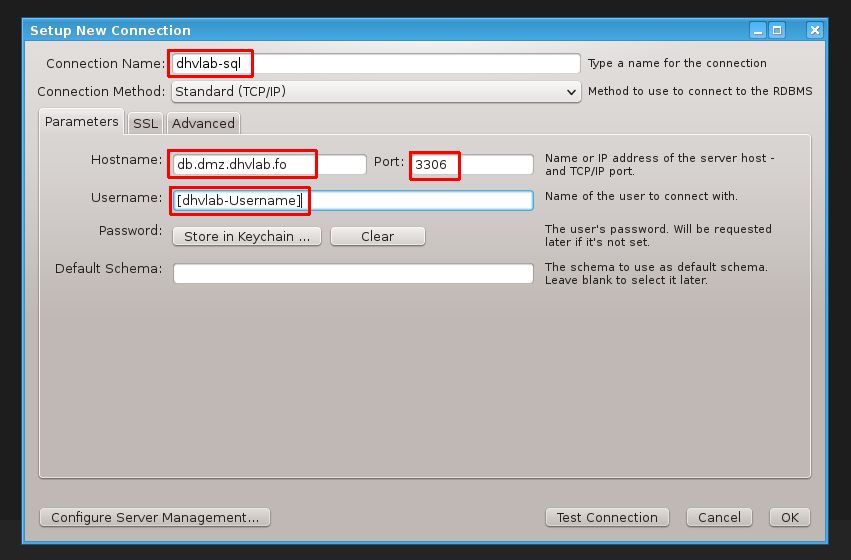
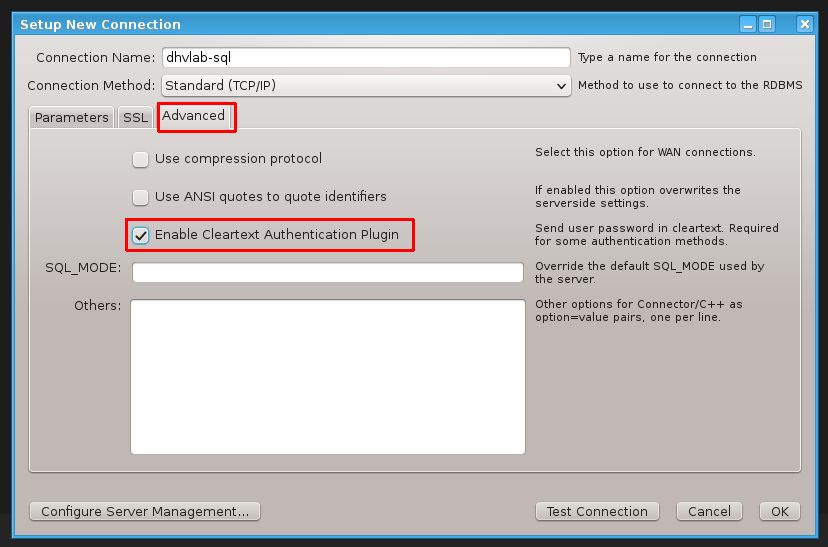
Wenn Sie zu einer bestehenden Datenbank verbinden möchten, gehen Sie wie folgt vor.
- Klicken Sie im Startmenü von MySQL Workbench neben "MySQL Conncetions" auf das Plus-Symbol (vgl. Abb. 1)
- Geben Sie im sich öffnenden Kontextmenü die erforderlichen Angaben zur Verbindung ein (vgl. Abb. 2)
- Klicken Sie anschließend auf den Reiter "Advanced" und wählen Sie "Enable Cleartext Authentication Plugin" an (vgl. Abb. 3)
- Bestätigen Sie nun mit Klick auf "OK" und die Datenbank wird in Ihrem Startmenü als neue Schaltfläche angezeigt
- Doppelklicken Sie auf die Schaltfläche und geben Sie Ihr DHVLab-Passwort zum Aufbau der DB-Verbindung ein
- Es öffnet sich eine neue Arbeitsumgebung. Diese
verfügt über folgende (zentrale) Bereiche:
- Fenster Mitte: Eingabe und Absenden von SQL-Abfragen
- Fenster Unten: Output-Feld, in dem das Ergebnis Ihrer Abfragen angezeigt wird
- Fenster Rechts: Snippet-Menü, in dem die Syntax nützlicher SQL-Abfragen hinterlegt ist; hier können Sie auch Ihre eigenen SQL-Statements hinterlegen (via Klick auf das Symbol "Stern" über dem Eingabefeld in der Mitte) und zu einem späteren Zeitpunkt erneut durchführen
- Bereich Links Oben: Management; hier können Sie u.a. Daten(banken) importieren oder exportieren, oder Benutzerrechte verwalten
- Fenster Links Mitte: Anzeige der verfügbaren Datenbanken und zugehöriger Tabellen
- Fenster Links Unten : Anzeige von Informationen zur Tabellenstruktur beim Anklicken einer Tabelle
- Im Eingabefeld können Sie beliebig viele SQL-Abfragen eingeben und entweder einzeln oder gemeinsam absenden; Tipp: Ein Klick auf das Symbol "Pinsel" oberhalb des Eingabefeldes strukturiert Ihre SQL-Abfrage für eine bessere Lesbarkeit
- Mit Rechtsklick auf eine Tabelle im Menü (linke Spalte) können bestehende Tabellen editiert oder neue hinzugefügt werden; ebenso kann der Inhalt einer Tabelle ausgegeben und ggf. bearbeitet werden
- Änderungen an Daten innerhalb einer Tabelle werden durch Doppelklick auf das entsprechende Datenfeld vorgenommen
- Zum Speichern Ihrer Änderungen am Datenbestand klicken Sie auf "Apply", rechts unterhalb des Eingabefeldes
ER-Diagramm anlegen
Als de-facto-Standard bei der Datenmodellierung gilt das
Entity Relationship Modell, kurz ERM. Innerhalb
der MySQL Workbench-Umgebung gibt es
eine bequeme Möglichkeit, ER-Diagramme für neue Datenbanken anzulegen
oder sich für bestehende Datenbanken anzeigen zu lassen.
Wie Sie ein neues Datenbankmodell anlegen können, habe Sie oben
bereits kennengelernt.
- Um ein Diagramm Ihres Datenbankmodells anzuzeigen, doppelklicken Sie auf das Icon "Add Diagram".
- In einem neuen Fenster öffnet sich nun der Diagramm-Editor. Dort werden alle vorhandenen Tabellen und ihre zugehörigen Verknüpfungen angezeigt (Fremdschlüssel-Verknüpfungen, verschiedene Kardinalitäten)
- Innerhalb des Editors können Sie nach Belieben neue Tabellen und Spalten anlegen und ergänzen. Diese erscheinen fortan auch in der Übersicht Ihres Datenbankmodells
- Möchten Sie das Datenmodell einer bestehenden Datenbank öffnen, gehen Sie wie folgt vor:
- Klicken Sie im oberen Kontextmenü auf Databases → Reverse Engineer
- Wählen Sie "dhvlab-sql" bei Stored Connection aus und geben Sie Ihr DHVLab-Passwort für die Verbindung zur Datenbank ein
- Wählen Sie nun die Datenbanken/Tabellen aus, die Sie im Folgenden angezeigt bekommen möchten
- Nun können Sie wie eben geschildert neue Tabellen/Spalten ergänzen und bestehende bearbeiten
- Haben Sie Änderungen vorgenommen, können Sie diese wie folgt übernehmen: Database → Synchronize Model
- Modelle können als mwb-Datei abgespeichert werden
Praktischer Einstieg in phpMyAdmin
Grundlegendes und Aufbau der Oberfläche
Mit
phpMyAdmin lernen Sie eines der populärsten
MySQL-Administrationswerkzeuge kennen. Es handelt sich dabei um eine
grafische, webbasierte Bedienoberfläche zur Verwaltung
Ihrer Datenbanken. Der Zugriff erfolgt unmittelbar über den Browser
(standardmäßig ist ein Google Chrome-Browser installiert), den Sie im
DHVLab (→ Hauptmenü) öffnen. Geben Sie in die Adresszeile folgenden Link
ein und melden Sie sich wie gewohnt mit Ihren Benutzerdaten an:
web.dmz.dhvlab.fo/sql1
Kennenlernen der Oberfläche
Es öffnet sich die Startseite der grafischen Benutzeroberfläche phpMyAdmin. Zunächst möchten wir uns mit der Oberfläche vertraut machen und dabei die Funktionsweise kennenlernen. Ein allgemeiner Hinweis vorne weg: Es können immer mehrere phpMyAdmin-Seiten parallel geöffnet sein.
Linke Spalte
Unter dem phpMyAdmin-Logo befinden sich einige Symbole mit zentralen
Funktionen: (1) Startseite, (2)
Logout, (3) Dokumentation2
sowie der (4) Refresh-Button. Letzterer sollte immer
die erste Wahl sein, wenn eine Änderung in der linken Tabellenspalte
nicht gleich angezeigt wird. Wichtiger Hinweis:
Verwenden Sie nicht den Vor- bzw.
Zurückbutton Ihres Browsers zum Navigieren innerhalb
der Oberfläche. Unterhalb der Navigation
befindet sich die Liste aller verfügbaren Datenbanken.
Im Zuge Ihrer Anmeldung im DHVLab wurde für Sie bereits eine
persönliche Datenbank angelegt
("labuser_mmustermann"); diese Datenbank finden Sie dort ebenso
wie Datenbanken, die für den von Ihnen besuchten Kurs angelegt wurden
und allgemeine Forschungsdatensammlungen, auf die Sie
Lesezugriff besitzen (z.B. "all_art_moma" (Daten des Museum
of Modern Art)). Um mit den Forschungsdatensammlungen
arbeiten zu können, kopieren Sie diese (Struktur und Daten) in Ihre
eigene Datenbank:
Operationen → "Kopiere Tabelle nach" → wählen Sie dort Ihre persönliche Datenbank aus und bestätigen Sie mit "OK"
Operative Ebene
Am oberen Bildrand wird Ihnen die dunkelgraue Statusleiste angezeigt. Klicken Sie in der linken Spalte auf eine beliebige Datenbank, so wird die detaillierte Pfadangabe in der genannten oberen Leiste angezeigt. Darunter befindet sich die operative Ebene ("Datenbanken", "SQL", "Status", "Exportieren", "Importieren", "Einstellungen", "Mehr").
Einstellungen:
Unter "Einstellungen" können Sie die Anzeige der
phpMyAdmin-Umgebung nach Ihren Wünschen optimieren. Wir
möchten an dieser Stelle nur eine exemplarische Veränderung
vornehmen: Standardmäßig wird neben jeder Tabellenspalte die
Option "Bearbeiten" und "Löschen" angegeben. Alternativ kann man sich
diese Operationen auch als platzsparende Symbole anzeigen lassen. Wir
gehen wie folgt vor:
"Einstellungen" → "Hauptpanel" → Anzeigemodus → "Wie verschiedene Aktions-Links angezeigt werden": Symbole → abschließen durch Klick auf "Übernehmen"
SQL:
Unter "SQL" findet sich die Eingabemaske für
SQL-Abfragen. Sie können dort beliebige SQL-Eingaben vornehmen.
Sinnvollerweise wählen sie zuvor die Tabelle aus, die Sie bearbeiten
möchten. Dadurch erhalten Sie zum Einen bereits eine
vorgefertigte SQL-Abrage
(SELECT * FROM `tabellenname` WHERE 1), zum Anderen finden
Sie rechts neben der Eingabemaske eine Liste aller in der
Tabelle verfügbaren Spalten. Ein Doppelklick auf einen
Spaltenname fügt diesen an der aktuellen Cursor-Position in der
Eingabemaske ein. Zudem finden Sie unter der Eingabemaske verschiedene
Abfragearten
(SELECT *, SELECT, INSERT, UPDATE, DELETE3),
die Sie durch einen einfachen Klick anwählen können. Wir werden auf die
SQL-Abrfragen im nächsten Kapitel zurückkommen.
Exportieren:
Wählen Sie zunächst die Datenbank oder Tabelle aus, die Sie aus der SQL-Datenbank exportieren möchten. Klicken Sie anschließend auf "Exportieren" in der operativen Ebene. Bei "Art des Exports" können Sie es in der Regel "Schnell - nur notwendige Optionen anzeigen" belassen. Bei "Format" können Sie zwischen einer Reihe an Ausgabeformaten wählen. Sinnvollerweise speichern Sie Ihre Ausgabe entweder als SQL-File4 oder als CSV5, zur Weiterverarbeitung in einem Tabellenkalkulationsprogramm wie Excel/Calc oder auch zum Einlesen in graphbasierte Datenbanken.
Importieren:
Neben dem Export von Daten können Sie selbstverständlich auch Daten
in Ihre Datenbank importieren6.
Beachten Sie stets, in
welcher Navigationsebene Sie sich aktuell befinden,
bevor Sie auf "Importieren" klicken. Die zu importierende Datei wird
genau dort eingefügt. Wählen Sie eine Datei aus, die Sie importieren
möchten. Wählen Sie dann das Format der ausgewählten
Datei aus. Wenn Sie als Dateiformat CSV auswählen, müssen Sie bei den
nun angezeigten "Formatspezifischen Optionen" noch
spezifizieren, durch welches Zeichen die einzelnen Spalten in der Datei
getrennt werden (z.B. ",", ";",
"\t"). Um dies zu ermitteln, werfen Sie zuvor mit einem
Texteditor einen Blick in die CSV-Datei. Mit Klick auf
"OK" schließen Sie den Import der Tabelle ab. Sie wird an der
entsprechenden Stelle in der linken Auflistung angeführt7.
Aufgabe: Erstellen Sie über den eben beschriebenen Weg einen SQL-Dump einer beliebigen Tabelle aus Ihrer Datenbank. Öffnen Sie anschließend die Datei in einem Texteditor Ihrer Wahl (z.B. Notepad++, gvim, UltraEdit) und sehen Sie sich die Struktur des Inhaltes an. Sie werden sehen, dass alle Informationen in dem Format wiederzufinden sind, wie Sie es in Ihrer Tabelle zuvor definiert haben. Löschen Sie im Anschluss die entsprechende Tabelle aus Ihrer SQL-Datenbank. Importieren Sie anschließend das SQL-Backup wiederum in Ihre Datenbank. Ihre Tabelle ist nun wieder vollumfänglich nutzbar.
Allgemein gilt: Alle Aktionen können auch über den entsprechenden
SQL-Befehl erfolgen8. Für den eben
geschilderten Import
einer CSV-Datei würde der entsprechende SQL-Befehl wie folgt
aussehen:
LOAD DATA LOCAL INFILE '[pfad]/[ergänzen]/dateiname.csv' INTO TABLE `tabellenname` FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
Bedeutung der einzelnen Bestandteile:
LOAD DATA LOCAL INFILE |
Zieltabelle angeben |
INTO TABLE |
Zieltabelle angeben |
FIELDS TERMINATED BY |
Symbol zum Trennen der CSV-Felder |
ENCLOSED BY |
Symbol am Anfang und am Ende eines CSV-Feldes |
LINES TERMINATED BY |
Symbol am Ende des jeweiligen Datensatzes (\n = New Line) |
IGNORE 1 ROWS |
Ignoriert die erste Zeile, weil diese z.B. Metainformationen enthält |
Wählen Sie die importierte Tabelle aus und es wird standardmäßig zunächst ihr Inhalt angezeigt. Unter "Struktur" können Sie sich die Tabellenstruktur ansehen, bearbeiten, kopieren oder löschen. Tabellen bestehen aus mehreren Spalten; diese haben jeweils einen Namen, einen Datentyp und eine Kollation:
- Spaltennamen können beliebig gesetzt werden
- Der Datentyp definiert, welche und wie viele Zeichen in einer Spalte vorkommen können.
- Dimensionierung: Bestimmte Datentypen erfordern die Angabe der maximalen Feldbreite. Achten Sie darauf, stets genug Spielraum bei der Zeichenzahl zu gewähren; ist die maximale Zeichenzahl zu niedrig angesetzt, werden die Einträge entsprechend abgeschnitten.
- Kollation: Bei MySQL kommt standardmäßig der
8-bit-Zeichensatz Latin1 zum Einsatz (latin1_swedish_ci).
Dieser Zeichensatz enthält zwar die deutschen Umlaute, bei Sonderzeichen
wie dem Euro-Symbol wird es dagegen schon problematisch. Alternativ
sollte daher auf UTF-8 zurückgegriffen werden, welches
weit umfassendere Kodierungen ermöglicht. bei diesem Zeichensatz werden
die ersten 128 Zeichen des ASCII-Zeichensatzes (7 bit) in einem Byte
kodiert, alle anderen in zwei bis vier Bytes.
Für ausführliche Informationen zur Zeichenkodierung,
schwerpunktmäßig mit der Frage nach Groß- und
Kleinschreibung (case-sensitive vs.
case-insensitive =
Zusatz"_ci" bei Kollation) siehe:
Dh-Lehre
- NULL: In diesem Feld kann angegeben werden (ja/nein), ob ein Tabellenfeld leer bleiben darf, d.h. ohne Inhalt, oder nicht (eine ID-Spalte darf zum Beispiel nie leer sein). NULL sollte nur dann verwendet werden, wenn eine leere Zelle (d.h. nicht NULL) in einer Anwendung falsch interpretiert werden könnte (z.B. bei Geokoordinaten).
- Primärschlüssel (unter "Aktion"): Ein Primärschlüssel kann einer Tabellenspalte zur eindeutigen Identifizierung zugewiesen werden.
- Auto Increment (A I') via "Aktion" → "Bearbeiten": Wenn jedem Eintrag einer Tabelle automatisch eine fortlaufende ID zugeteilt werden soll, so wird für dieses Feld "Auto Increment" angewählt.
Datentypen
Es seien an dieser Stelle nur einige gängige Datentypen angeführt:
| Datentyp | Beschreibung |
|---|---|
| INT (3) | Integer, Ganzzahlen inkl. 0; Länge bestimmt Anzahl der Ziffern, hier z.B. 3 |
| DECIMAL (5) | Dezimalzahlen; Länge bestimmt Anzahl der Ziffern, hier z.B. 5 |
| FLOAT(10,6) | Gleitkommazahlen; eignet sich z.B. für die Eingabe von Geokoordinaten (10,6): 48.137222 |
| ENUM | Vordefinierte Auswahlliste; dadurch nur begrenzte Möglichkeiten bei der Zuweisung von Attributen, z.B. Auswahl Geschlecht: m, w |
| CHAR (10) | Beliebige Zeichenkette ("Strings") mit fester Breite im Speicher, hier z.B. 10. |
| VARCHAR (240) | Various Character; Länge bestimmt die maximale Anzahl der Zeichen, hier z.B. 240 (maximal: 65535 Zeichen), jedoch auch weniger Zeichen möglich |
| TEXT | Zeichenkette bis maximal 65535 Zeichen, max. Gesamtzeichenzahl im Gegensatz zu VARCHAR nicht kürzer definierbar |
| LONGTEXT | Zeichenkette im Umfang von 4.294.967.295 Buchstaben (max. 4 GB) |
| DATE (2016-08-06) | Datumsangabe (yyyy-mm-dd); DATE ist nur sinnvoll bei modernen Datumsangaben ab etwa 1970. Bei früheren Angaben kann es passieren, dass eine MySQL-Installation die Angabe falsch interpretiert und entsprechend umformt. Bei historischen Datumsangaben sollte daher stets auf VARCHAR zurückgegriffen werden. Bei Datumsangaben ohne Tagesdatum gilt es zu bedenken, dass es sich sowohl um den 1. als auch um den 31. eines Monats handeln kann. Eine entsprechende Modellierung ist daher erforderlich. |
| DATETIME (2016-08-06 23:59:01) | Datumsangabe mit Uhrzeitangabe (yyyy-mm-dd 00:00:00) |
| PRIMARY(INT) | Primärschlüssel, angelegt über Index, AutoIncrement aktivieren |
| CONSTRAINT ... REFERENCES | Definition von Fremdschlüsselspalten |
| CONSTRAINT ... NOT NULL | Erzwingen von Eingabewerten; ein Feld dieser Spalte darf nicht leer bleiben |
| UNIQUE | In einer UNIQUE-Spalte dürfen keine zwei identischen Elemente vorhanden sein. |
Neben dem Import einer Tabelle kann man mit Hilfe von SQL Tabellen in pypMyAdmin anlegen und in diese später Daten importieren. Mit folgender Eingabe wird eine neue Tabelle angelegt, die über eine fortlaufende ID-Spalte verfügt, die gleichzeitig den Primärschlüssel für die Tabelle darstellt:
CREATE TABLE Historiker
(
historikerID int NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
vorname VARCHAR(255),
einrichtung VARCHAR(255),
ort VARCHAR(255)
);
Anmerkungen
- Alternativ können Sie auch außerhalb des DHVLab auf die MySQL-Umgebung zugreifen. Geben Sie hierzu folgende Adresse in Ihren Browser ein: http://dhvlab.gwi.uni-muenchen.de/sql/.↩︎
- Hierüber gelangt man zur offiziellen MySQL-Dokumentation, ein umfassendes Manual, welches keine Fragen offen lassen sollte: 1↩︎
- Achtung: Der
DELETE-Befehl sollte mit nur mit größter Vorsicht verwendet werden; einmal gelöscht, sind die Daten unwiderruflich verloren.↩︎ - Ein SQL-Backup wird auch als "SQL-Dump" bezeichnet. Es empfiehlt sich zum Absichern der Daten, regelmäßig ein solches Backup Ihrer gesamten Datenbank durchzuführen.↩︎
- CSV (Comma Separated Values): Bei CSV handelt es sich um ein einfaches relationales Dateiformat, bei dem jede Zeile einen Datensatz darstellt. Jeder Datensatz wiederum besteht aus mehreren Spalten, die durch ein Komma, Semikolon oder Tabstopp getrennt sind. Die Daten jeder Spalte werden durch Anführungszeichen ("...") eingeschlossen. Eine CSV-Datei können Sie aus einer bestehenden Calc/Excel-Tabelle erzeugen ("Speichern unter").↩︎
- Zum Folgenden ausführlich das Handbuch von Stephan Lücke auf dh-lehre.↩︎
- Für den Import sehr großer SQL-Dateien empfiehlt sich das Programm "mysqlimport"; vgl. hierzu DH-Lehre.↩︎
- Bei jeder datenverändernden Aktion, die über die Schaltflächen ausgeführt wird, wird der zugehörige SQL-Befehl angezeigt. Dies ist für das Erlernen der Abfragesprache nützlich.↩︎
Erlernen einer Datenbanksprache: Structured Query Language (SQL) I
Einstieg in SQL
Im vorangehenden Abschnitt sind wir bereits zwei Mal mit der Datenbanksprache SQL in Kontakt gekommen, zum Einen beim Import einer CSV-Datei, zum Anderen bei der Erstellung einer Tabelle. Die beiden zugehörigen SQL-Befehle seien an dieser Stelle zur Erinnerung noch einmal angeführt:
- Anlegen einer Tabelle in phpMyAdmin (mit
fortlaufender ID-Spalte, zugleich Primärschlüssel):
CREATE TABLE Historiker
(
historikerID int NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(255),
vorname varchar(255),
einrichtung varchar(255),
ort varchar(255)
); - Import einer CSV-Datei in die Datenbank:
LOAD DATA LOCAL INFILE '[pfad]/dateiname.csv' INTO TABLE `tabellenname` FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
Es ist also an der Zeit, dass wir uns nun umfassend mit der Structured Query Language auseinandersetzen. Ein paar grundlegende Informationen zu SQL:
- SQL ist semantisch an die englische Umgangssprache angelehnt und besitzt eine relativ einfach aufgebaute Syntax
- Der Bestandteil "Query" bezieht sich auf eine der Hauptaufgaben der Sprache: Das Abfragen von, in einer Datenbank vorgehaltenen Daten, um sie dem/der Benutzer/in oder einer Anwendersoftware zur Verfügung zu stellen
- SQL unterscheidet nicht zwischen Groß- und Kleinschreibung in den Befehlen. Im Folgenden werden die SQL-Befehle stets in Großbuchstaben geschrieben, um die Syntax besser verständlich zu machen. Dies ist im Anwendungsfall nicht zwangsläufig erforderlich.
- Abfrageergebnisse werden stets als neue Tabelle ausgegeben und sind beliebig weiter verarbeitbar.
SQL: DDL, DCL und DML
Die Abfragen/Befehle der Datenbanksprache SQL lassen sich in drei Kategorien unterteilen:
- Data Definition Language (DDL)
- Data Control Language (DCL)
- Data Manipulation Language (DML)
DDL: Datenstrukturen anlegen,
ändern
Der oben angeführte Befehl zur Erstellung einer
Tabelle gehört zur DDL, da er ein Datenbankschema definiert. Neben
CREATE TABLE existieren in SQL u.a. folgende
DCL-Befehle:
| SQL-Eingabe | Beschreibung |
|---|---|
ALTER TABLE Historiker ADD Postleitzahl int(5) |
Ergänzt in der Tabelle 'Historiker' eine Spalte namens 'Postleitzahl' mit der Länge von 5 Zeichen |
DROP TABLE Historiker |
Löscht die Tabelle 'Historiker' |
CREATE INDEX idx_name ON Historiker (name) |
Zur Beschleunigung der Suche nach Datensätzen in der Tabelle 'Historiker' wird eine Index mit der Bezeichnung idx_name angelegt. |
DROP INDEX idx_name |
Der eben angelegte Index kann selbstverständlich auch wieder gelöscht werden |
DCL: Verwaltung von
Zugriffsrechten
Mit DCL können Berechtigungen
innerhalb des DBMS vergeben werden; da dies für uns nicht so
sehr von Relevanz ist (noch sind wir keine Datenbank-Admins), werden wir
gleich zu DML übergehen.
DML:
Die Datenbearbeitungssprache DML
ermöglicht uns das Auswählen (SELECT),
Einfügen (INSERT INTO),
Ändern (UPDATE) und
Löschen (DELETE FROM/TRUNCATE TABLE) von
Daten innerhalb von Tabellen1. Mit
dieser Art von
Datenbankanfragen werden wir am häufigsten in unserer tagtäglichen
Arbeit mit relationalen Datenbanken konfrontiert. Im Folgenden werden
wir uns wichtige Datenbankanfragen näher ansehen.
Datenbankanfragen (DML/DQL): Daten lesen, schreiben, ändern, löschen
Mit Hilfe von SQL können Anfragen an eine relationale Datenbank gestellt werden2. Ein Parser zerlegt die Anfrage in ihre einzelnen relationalen Operatoren, um mit Hilfe der daraus gewonnenen Informationen die durch den Nutzer gestellte Anfrage zu beantworten.
Grundform einer Datenbankanfrage
SELECT * (* steht für "all"; es kann auch gezielt nach
einen oder mehrere Attributsnamen gesucht werden, durch Kommata
getrennt)
FROM (ein oder mehrere
Tabellenname)
WHERE (Bedingung)
Optionale Ergänzungen:
GROUP BY
(Zusammenfassung mehrerer Zeilen mit demselben Attribut)
HAVING (Bedingung; z.B. nur wenn mehr als drei Vorkommen
eines Attributs)
ORDER BY (Sortierung nach
einem bestimmten Attribut)
Grundlegende Hinweise zur Grundform einer Datenbankanfrage:
- Die SQL-Syntax ist in funktionale Einheiten gegliedert, die man Klauseln nennt (z.B. SELECT-Klausel, WHERE-Klausel).
- Es müssen nicht alle dieser Klauseln in einer Anfrage vorkommen.
- Die oben angeführte Reihenfolge muss jedoch immer eingehalten werden.
- SQL-Befehle werden stets mit einem Semikolon abgeschlossen.
- Möchten Sie eine abgeschickte Anfrage abändern, so genügt ein Klick auf "Inline bearbeiten" unterhalb des angezeigten SQL-Befehls.
- Sobald Sie beginnen, eine SQL-Klausel einzugeben, werden Ihnen über die Autovervollständigung Eingabemöglichkeiten angezeigt.
- Senden Sie eine fehlerhafte SQL-Anfrage ab, wird Ihnen eine Fehlermeldung ausgegeben. Diese kann (muss aber nicht immer) hilfreich sein, um dem Fehler auf den Grund zu gehen (z.B. wenn eine schließende Klammer fehlt oder ein Anführungszeichen falsch gesetzt wurde).
- Zeilenumbrüche und Leerzeichen können beliebig im Code gesetzt werden; dies empfiehlt sich aus Gründen der besseren Übersichtlichkeit.
- Abfrageergebnisse können unmittelbar exportiert bzw. als neue Tabelle abgespeichert werden.
Verschiedene Datenbankanfragen
Einfache Abfrage (= Selektion)
~ Geben Sie eine Anfrage
an die Datenbank ein, um sich die Tabelle 'Historiker' komplett ausgeben
zu lassen.
SELECT * FROM `historiker`;"
Abfrage mit Auswahl der Spalten (= Projektion)
~ Geben
Sie eine Anfrage an die Datenbank ein, um sich von der Tabelle
'Historiker' nur die Spalten `vorname` und `name` ausgeben zu
lassen.
SELECT `vorname`, `name` FROM `Historiker`;
- Bei einer Selektion können einzelne Spalten ausgewählt werden
- Die Liste der Feldnamen ist kommagetrennt, hinter dem letzten Feldnamen vor der FROM-Klausel darf kein Komma stehen!
- Die Reihenfolge der Spalten kann bei der Ausgabe verändert werden
- Spalten können bei der Ausgabe beliebig oft ausgewählt werden
Distinct-Abfrage
~ Geben Sie eine Anfrage an die Datenbank ein, um sich von der
Tabelle 'Historiker' alle vorhandenen Unistandorte nur einmal ausgeben
zu lassen (nicht zu verwechseln mit GROUP BY).
SELECT DISTINCT `ort` FROM `Historiker`;
Gefilterte Abfrage
~ Geben Sie eine Anfrage an die Datenbank ein, um sich von der
Tabelle 'Historiker' nur die Spalten `vorname` und `name` der Historiker
ausgeben zu lassen, die in München wohnhaft sind.
SELECT `vorname`, `name` FROM `Historiker` WHERE `ort` = 'München';
Abfrage mit HAVING-Klausel
~ Geben Sie eine Anfrage an die Datenbank ein, um sich von der
Tabelle 'Historiker' die Anzahl der Historiker pro Universitätsstandort
ausgeben zu lassen, jedoch mit der Bedingung, dass dort mehr als 10
Historiker tätig sind.
SELECT COUNT(`id`), `ort` FROM `Historiker` GROUP BY `ort` HAVING COUNT(`id`) > 10;
- Die HAVING-Klausel kann im Gegensatz zur WHERE-Klausel in Verbindung mit Aggregatfunktionen3 wie COUNT eingesetzt werden.
Limitierung des Abfrageergebnis
~ Geben Sie eine Anfrage an die Datenbank ein, um sich von der
Tabelle 'Historiker' die Spalten `vorname` und `name` nur der
ersten fünf Historiker ausgeben zu lassen, die in München
wohnhaft sind.
SELECT `vorname`, `name` FROM `Historiker` WHERE `ort` = 'München' LIMIT 5;
- Es ist ebenso möglich, sich aus der Ergebnismenge nur eine Anzahl
ausgeben zu lassen:
... FROM `Historiker` LIMIT 2, 5. In diesem Fall würden fünf Datensätze ausgegeben, beginnend beim zweiten Datensatz, d.h. Datensatz 3-7.
Einschub: Operatoren, Platzhalter, Anführungszeichen, Kommentare
Der "SFW"-Block (SELECT,
FROM, WHERE) bzw. die
"WHERE-Klausel" erlauben eine Selektion einzelner
Zeilen aus einer Tabelle, deren Inhalte einem bestimmten Muster
entsprechen.
Für die Selektion
stehen verschiedene, i.d.R. beliebig kombinierbare
Operatoren zur Wahl (Beispielabfragen siehe unten):
| Operator | Funktion |
|---|---|
=
|
absolute Übereinstimmung zwischen Suchanfrage und Feldinhalt |
!= oder <>
|
absolut keine Übereinstimmung zwischen Suchanfrage und Feldinhalt |
>= |
Größer oder gleich |
<= |
Kleiner oder gleich |
LIKE |
relative Übereinstimmung zwischen Suchanfrage und Feldinhalt. Der LIKE-Operator ermöglicht eine trunktierte Suche unter Verwendung von Platzhaltern |
Für die trunktierte Suche mit dem LIKE-Operator kommen folgende Platzhalter zum Einsatz:
| Platzhalter | Funktion (erklärt anhand eines Beispiel) |
|---|---|
% |
beliebig große Anzahl an Zeichen: Sch% -> Schulz; Scholz; Schneider etc. |
_ |
genau ein beliebiges Zeichen: Sch_lz -> Schulz; Scholz |
RLIKE |
ermöglicht die Suche nach regulären Ausdrücken, also einer abstrakten Darstellung von Zeichenketten |
NOT LIKE |
keine relative Übereinstimmung zwischen Suchanfrage und Feldinhalt |
AND, OR |
und / oder |
IS NULL, IS NOT NULL4 |
ermöglicht die Suche nach regulären Ausdrücken, also einer abstrakten Darstellung von Zeichenketten |
BETWEEN 'Zahl 1' AND 'Zahl 2' |
Definition eines numerischen Wertebereichs (Werte können Nummern, Daten oder Text sein). Anfangs- und Endwert sind mitinbegriffen. |
Beispielabfragen:
SELECT * FROM `Historiker` WHERE `name` LIKE 'M_mmsen' AND (Ort = 'Berlin' OR Ort = 'Bonn');
SELECT * FROM `Historiker` WHERE `ort` <> 'Berlin';
SELECT * FROM `Historiker` WHERE `postleitzahl` BETWEEN '85000' AND '89000';
SELECT * FROM `Historiker` WHERE `ort` IS NULL;
Wichtiger Hinweis: Gewiss sind Ihnen bereits die unterschiedlichen Anführungszeichen aufgefallen. Daher sei an dieser Stelle zum besseren Verständnis kurz auf die Unterschiede verwiesen5:
- Doppelte Anführungszeichen (" ") und einfache Anführungszeichen/Hochkommata (' ') können synonym verwendet werden, um eine Zeichenkette (String), also z.B. einen zu suchenden Text zu kennzeichnen. Sie dürfen jedoch nur einheitlich und nicht gemischt verwendet werden.
- Backticks6
finden bei Tabellen- und
Feldnamen Anwendung (SELECT `name` FROM `Historiker`). Ihre Verwendung
ist nicht obligatorisch, es sei denn wenn Tabellen-
oder Feldnamen
- von MySQL missinterpretiert werden könnten (z.B. SELECT `alter`7 FROM `Personen`;) oder
- ein Leerzeichen enthalten (z.B. `spalte 1`)
Kommentare:
Es besteht
die Möglichkeit, innerhalb von SQL-Statements Kommentare einzufügen, um
einzelne Bestandteile auszukommentieren. Um eine einzelne Zeile
auszukommentieren, setzt man zwei Minuszeichen, gefolgt von einem
Leerzeichen: --[Leerzeichen]. Nachfolgender Text wird bis zum Zeilenende
auskommentiert.
Um mehrere Zeilen, oder einen Bestandteil innerhalb einer Zeile
auszukommentieren, setzt man folgende Zeichenkombination: /* ... */
Gefilterte Abfrage mit Sortierung
~ Geben Sie eine Anfrage an die Datenbank ein, um sich von der
Tabelle 'Historiker' nur die Spalten `vorname` und `name` ausgeben zu
lassen, sortiert nach `vorname`
SELECT `vorname`, `name` FROM `Historiker` ORDER BY `vorname`;
Die Anordnung der Gruppierung lässt sich durch die Anfügung
DESC (= descending; absteigend) oder
ASC (= ascending; aufsteigend) bestimmen.
Standardmäßig wird aufsteigend sortiert.
- Es ist auch möglich, nach dem Inhalt mehrerer Spalten zu sortieren,
z.B:
ORDER BY `vorname` ASC, `nachname` DSC. In diesem Fall wird zunächst nach dem Vornamen (aufsteigend), dann nach dem Nachnamen als zweites Kriterium (absteigend) sortiert.
Abfrage unter Zuteilung von Korrelationsnamen
SELECT `plz` AS Postzeitzahl, `ort` AS Universitätsstandort FROM `Historiker` ORDER BY `vorname`;
Bei der Ausgabetabelle werden die entsprechenden Spalten mit den
Korrelationsnamen überschrieben. Sinnvoll ist dies v.a.
bei der Abfrage mit verknüpften Tabellen (Joins), der wir uns weiter
unten zuwenden werden. Alternativ können Aliasnamen auch wie folgt
vergeben werden:
SELECT `plz` "Postzeitzahl", `ort` "Universitätsstandort" FROM `Historiker` ORDER BY `vorname`;
Einfügung von Werten in eine bestehende Tabelle
INSERT INTO `Historiker` (`vorname`, `name`) VALUES (Theodor, Mommsen), (Theodor, Schieder);
Soll ein Feld ohne Inhalt bleiben, so kann "NULL" gesetzt oder der
entsprechende Feldname weggelassen werden. Die Reihenfolge der
Werte muss jedoch immer mit der der Tabellenspalten
übereinstimmen.
INSERT INTO tabelle2 (id, spalte2, spalte3) SELECT id, spalte2, spalte3 FROM tabelle1 WHERE id > 2;
Mit INSERT INTO ... SELECT können in gleicher Weise
Datensätze aus einer Tabelle 1 in eine Tabelle
2 überführt werden. Die bereits vorhandenen Daten in Tabelle 2
bleiben davon unberührt. Die Datentypen in Tabelle 1
und 2 müssen übereinstimmen.
Werte in neue Tabelle überführen
SELECT spalte1, spalte3, ... INTO neuetabelle FROM altetabelle WHERE [Bedingung];
Die neue Tabelle wird mit den Spaltennamen und Datentypen der
alten Tabelle erstellt. Um neue Spaltennamen zu vergeben, teilen Sie in
der Abfrage Korrelationsnamen zu.
Aktualisierung eines Wertes in einer bestehenden Tabelle
UPDATE `Historiker` SET `vorname` = 'Theodor' WHERE `name` = 'Schieder';
UPDATE `Historiker` SET `vorname` = 'NULL' WHERE `id` = 92;
Um den Inhalt eines Feldes zu löschen wird "NULL" gesetzt.
Löschen eines Tabellenbereiches
DELETE FROM `Historiker` WHERE `id` < 197;
Zwei wichtige Hinweise:
- Verwechseln Sie nicht die beiden Zeichen < und > !
- Vergessen Sie nicht, eine WHERE-Klausel zu verwenden, da sonst ALLES aus der Tabelle gelöscht wird.
Löschen des gesamten Tabelleninhalts
DELETE FROM `Historiker`
Der DELETE-Befehl
ohne WHERE-Klausel tilgt alle Daten, die Tabellenstruktur bleibt jedoch
erhalten.
Beachten Sie: Der Befehl wird unwiderruflich
durchgeführt; Sie werden vor Absenden des Befehls nicht mehr gewarnt.
Anmerkungen
- Teilweise wird auch von DQL (Data Query Language) gesprochen, wenn Daten nur abgefragt und nicht manipuliert werden.↩︎
- Wie bereits bei den anderen Operationen kann in phpMyAdmin auch die Suche ohne den Einsatz von SQL über die entsprechende Suchmaske (via "Suche" in der operativen Leiste) erfolgen. Nach dem Abschicken einer Suchanfrage wird Ihnen jeweils die zugehörige SQL-Anfrage mit ausgegeben.↩︎
- Zu Funktionen vgl. ausführlich die nachfolgende Seite dieses Manuals.↩︎
- NULL bedeutet "Feld ohne Werte", d.h. bei Erstellung des Datensatzes wurde kein Wert eingetragen. NULL ist nicht zu verwechseln mit leeren Strings (von der Zeichenlänge 0).↩︎
- Fileformat: Diese Seite ist allgemein zu empfehlen, wenn man sich über die Kodierung eines Zeichens informieren möchte.↩︎
- Vgl. hierzu den Eintrag in DH-Lehre↩︎
- Das Wort alter würde ansonsten als SQL-Operator interpretiert.↩︎
Erlernen einer Datenbanksprache: Structured Query Language (SQL) II (Funktionen, Joins, Union)
Einsatz von Funktionen
Im vorangehenden Kapitel haben wir die Grundlagen der
Datenbanksprache SQL kennengelernt und haben uns mit dem Aufbau der
Abfragen und verschiedenen Anwendungsbeispielen vertraut gemacht.
In SQL-Anfragen kann eine Vielzahl von Funktionen
zum Einsatz kommen. Funktionen haben stets den gleichen Aufbau: Eine
Funktion besteht aus dem Funktionsnamen, gefolgt von
einer sich öffnenden und schließenden Klammer (), ohne Leerzeichen.
Innerhalb der Klammern befinden sich der oder die
Parameter bzw. Argumente (= die
Daten), die an die Funktion übergeben werden. Funktionen können in fast
allen Klauseln eines SQL-Statements (u.a. Feld-Liste, WHERE-Klausel,
GROUP BY-Klausel) verwendet werden. Mit Hilfe von Funktionen können
praktische Veränderungen am Datenbestand vorgenommen
werden. Eine ausführliche Übersicht zu Funktionen mit
ausführlicher Funktionsbeschreibung bietet die MySQL-Dokumentation1.
Hinweis: Solange
sie nur Bestandteil einer SELECT-Abfrage sind, kann nichts
passieren! Es wird stets nur eine Ausgabe erzeugt und
keine dauerhafte Änderung am Datenbestand vorgenommen.
Funktionen in SQL - eine Auswahl
Im Folgenden sollen nur ein paar grundlegende Beispiele vorgestellt werden, um die Wirkung von Funktionen zu verdeutlichen.
| Funktion | Beschreibung |
|---|---|
LENGTH(`name`) |
Feststellen der Länge einer Zeichenfolge |
CONCAT(`vorname`, ,`name`) |
Ausgabe von Vorname und Name in einer Spalte, getrennt durch ein Leerzeichen |
CONCAT(`<person>`,`vorname`, ,`name`,`</person>`)
|
Beispiel für das beliebige Einbinden von Zusätzen, hier der XML-Tags um Vor- und Nachname |
REVERSE(`name`) |
Ausgabe des Feldinhalts innerhalb einer Spalte in umgekehrter Reihenfolge |
UPPER(`name`) |
Ausgabe des Feldinhalts innerhalb einer Spalte ausschließlich in Großbuchstaben |
LOWER(`name`) |
Ausgabe des Feldinhalts innerhalb einer Spalte ausschließlich in Kleinbuchstaben |
REPLACE(`name`,`oe`,`ö`) |
Ersetzt alle oe-Fälle durch ö in der Spalte `name` |
LEFT(spaltenname, 10) / RIGHT(spaltenname, 10) |
Ausgabe einer bestimmten Anzahl von Zeichen einer Zelle in einer
Spalte, beginnend von rechts oder links; z.B.:
SELECT CONCAT(LEFT(vorname, 1), LEFT(nachname, 2)) FROM Historiker;
→ "Peter Maier": "PMa"
|
COUNT(*) |
Zählen der Häufigkeit eines gewünschten Parameters und Ausgabe
des Ergebnisses als Zahl; z.B.:
COUNT(*) AS Anzahl FROM `Historiker` WHERE `ort` = 'München';
|
MIN(), MAX(), SUM(), AVG() |
Neben COUNT() gibt es weitere Aggregatsfunktionen. Sie fassen die Werte mehrerer (gruppierter) Zeilen zu einem Ausgabewert zusammen. |
Die letztgenannten mathematischen Funktionen spielen
neben Stringfunktionen2
und
Gruppierungsfunktionen (insb. COUNT() und
GROUP_CONCAT()) bei der Beantwortung
korpuslinguistischer Fragestellungen eine gesteigerte
Bedeutung3.
Anwendungsbeispiel einer Funktion: COUNT()
~ Bei folgender Ausgabe wird jeder Ort mit der jeweiligen Anzahl an
Vorkommen angeführt, wobei durch "GROUP BY" die Zeilen mit gleichem
Gruppierungswert zu einer Zeile zusammengefasst werden:
SELECT `ort`, count(*) AS Anzahl FROM `Historiker` GROUP BY `ort`;
~ Nun zeigt diese Anfrage jedoch zu jedem Ort
nur eine der zahlreichen zugehörigen Personen an4.
Die Lösung des Problems:
SELECT `ort`, count(*) AS Anzahl, GROUP_CONCAT(`name`, ',', `vorname`) FROM `Historiker` GROUP BY `ort`;
Damit werden nun alle Orte mit ihrem Vorkommen und innerhalb der
einzelnen Ortsspalte auch die zugehörigen Personen angezeigt.
~ Da die
Gruppenkonkatenierung standardmäßig auf 1024 Zeichen
begrenzt ist, muss diese möglicherweise durch die Ergänzung folgenden
Kommandos umgangen werden:
SET SESSION GROUP_CONCAT_MAX_LEN = 100000
Man kann die
Ausgabe nun noch
weiter verfeinern:
~ Zeilenumbruch zwischen
den einzelnen Namen ergänzen:
SELECT `ort`, count(*) AS Anzahl, GROUP_CONCAT(`name`, ',', `vorname` SEPARATOR '\n') FROM `Historiker` GROUP BY `ort`;
~ Zuweisen eines Spaltennamens und alphabetische Sortierung der
Namen:
SELECT `ort`, count(*) AS Anzahl, GROUP_CONCAT(`name`, ',', `vorname` ORDER BY `name` SEPARATOR '\n') AS 'Historiker' FROM `Historiker` GROUP BY `ort`;
~ Die Mit Hilfe von GROUP BY ermittelte Anzahl an Zeilen könnte
schließlich noch durch eine HAVING-Klausel eingeschränkt werden. Die
Bedingung einer HAVING-Klausel bezieht (im Unterschied zu WHERE) immer
auf das Ergebnis einer Aggregationsfunktion (vgl. vorangehende
Seite):
SELECT `ort`, count(*) AS Anzahl, GROUP_CONCAT(`name`, ',', `vorname` ORDER BY `name` SEPARATOR '\n') AS 'Historiker' FROM `Historiker` GROUP BY `ort` HAVING COUNT(*) > 20;
Es würden nun also nur sämtliche Universitätsstandorte aufgelistet
werden, denen jeweils mehr als 20 Historiker in der Datenbank zugeordnet
wurden.
Endergebnis: Es wird damit eine
sehr übersichtlich gestaltete Anzeige ausgegeben. Für eine anschließende
Visualisierung erscheint eine gewichtete Abfrage zur statistischen
Auswertung anstelle der absoluten Werte sinnvoll; auf gewichtete
Abfragen werden wir im folgenden Kapitel zurückkommen.
Verknüpfung von Tabellen: Joins
Bisher haben wir jeweils nur mit einer Tabelle gearbeitet. Das war
für das Kennenlernen der einzelnen Bestandteile von SQL-Abfragen
sinnvoll. Nun möchten wir uns den Joins und damit mit
der Möglichkeit, verbundener Tabellenabfragen,
zuwenden5. Mit Hilfe der IDs
können (beliebig
viele) verschiedene Tabellen und ihre Inhalte in Verbindung gesetzt
werden. Bildlich gesprochen werden mehrere Tabellen nebeneinander
gelegt. Es bestehen verschiedene Arten von Joins. Im
Folgenden sollen die für die Arbeit mit Datenbanken wichtigsten Joins
(INNER JOIN, LEFT/RIGHT JOIN,
FULL OUTER JOIN) vorgestellt werden.
Wir werden
mit drei Beispieltabellen arbeiten
(Konzeption: Stephan
Lücke (ITG)):
— cports = eine Liste an
Mittelmeerhäfen, die von verschiedenen Fährlinien angesteuert
werden
— cbetreiber = Liste der betreibenden
Fährunternehmen
— cconnections = Auflistung aller
Fährverbindungen zwischen den Häfen unter Angabe des Betreibers und der
saisonalen Verfügbarkeit
Die Beispieltabellen befinden sich
in der Datenbank "lab_dhsummerschool1". Kopieren Sie zunächst,
wie bereits beschrieben, die Tabellen in Ihre persönliche Datenbank
(labuser_mmustermann).
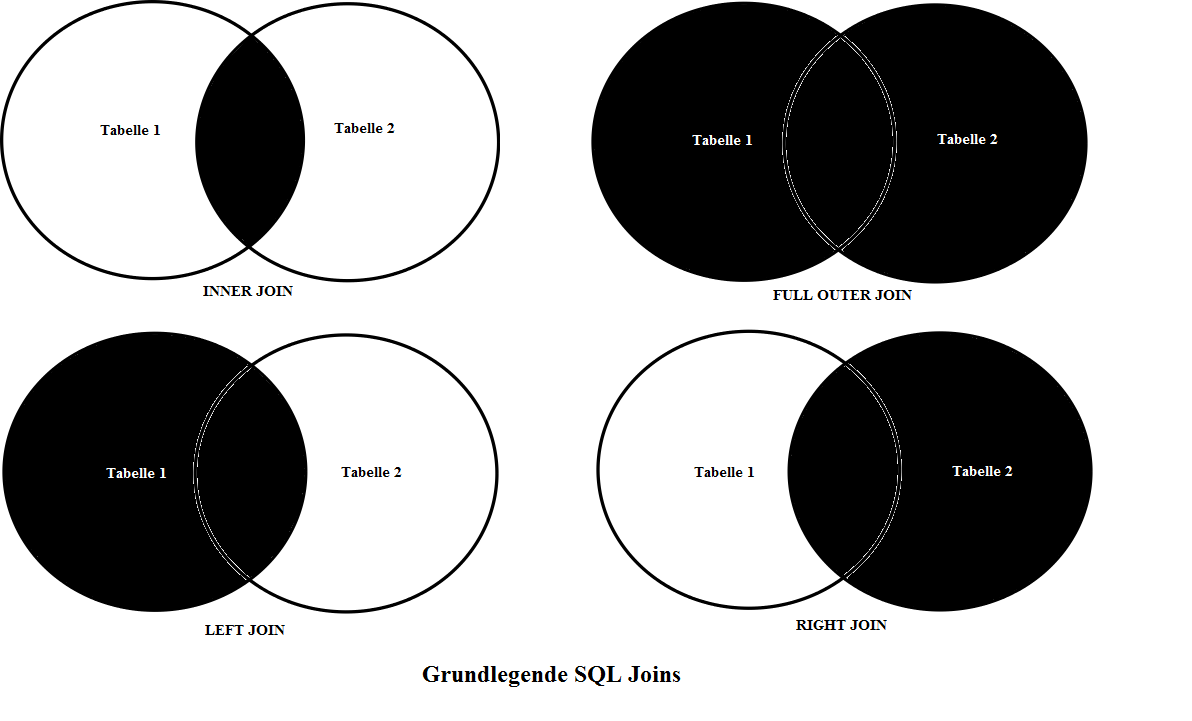
INNER JOIN
~ 'Joint' man zwei Tabellen miteinander, ohne dabei
ein Kriterium anzugeben, würde man ein
Kreuzprodukt (auch kartesisches
Produkt genannt) erhalten, d.h. eine Kombination aller Spalten
der Tabelle A mit allen Spalten der Tabelle B - einen Datenwust also,
der niemandem etwas nützt. Probieren Sie es dennoch einmal aus:
SELECT * FROM cconnections JOIN cbetreiber;
Die
Abfrage muss daher spezifiziert werden: Der
INNER JOIN führt all diejenigen Datensätze zweier
Tabellen zusammen, bei denen die im Join angegebenen Kriterien
erfüllt werden. Sobald ein Kriterium nicht erfüllt ist, taucht
der entsprechende Datensatz nicht in der Ausgabe auf. Wir
erweitern die eben getätigte Abfrage um eine
ON-Bedingung, in der der Inhalt der Spalte "betreiber"
aus Tabelle cconnections dem Inhalt der Spalte "betreiber" der Tabelle
cbetreiber entspricht:
SELECT * FROM cconnections JOIN cbetreiber ON (cconnections.betreiber = cbetreiber.betreiber);
Gleichlautende (ambiguous) Spaltennamen müssen durch das
Voranstellen des jeweiligen Tabellennamen, verbunden
durch einen Punkt, kenntlich gemacht werden. Um sich
gerade bei längeren Anfragen das immer wiederkehrende Eingeben der
Tabellennamen abzukürzen, kann man den Tabellen (wie schon gelernt)
Korrelationsnamen zuweisen; in unserem Fall:
cconnections wird dem Buchstaben 'a' zugewiesen, cbetreiber wird zu
'b':
SELECT * FROM cconnections AS a JOIN cbetreiber AS b ON (a.betreiber = b.betreiber);
Sie erhalten nun eine Ausgabe mit allen Informationen (weil: *)
beider Tabellen in einer Tabelle ausgegeben. Nehmen wir an, wir möchten
nur den Betreiber, den Start- und Zielhafen (hier erstmal nur in Form
der ID) und die Saison ausgegeben bekommen, so
schränken wir die Auswahl der Spalten
wie folgt ein:
SELECT aid, bid, saison, a.betreiber FROM cconnections AS a JOIN cbetreiber AS b ON (a.betreiber = b.betreiber);
Alternativ kann der INNER JOIN auch mit Hilfe der
USING-Funktion durchgeführt werden:
SELECT aid, bid, saison, a.betreiber FROM cconnections AS a JOIN cbetreiber AS b USING(betreiber);
(in diesem Fall entfällt der Tabellen-Zusatz)
SELFJOIN
Bei einem Selfjoin greift man zweimal auf
dieselbe Tabelle zu. Um die beiden Zugriffe voneinander zu
unterscheiden, weisen wir Korrelatsnamen (hier wiederum
a und b) zu. In unserem Fall sind alle Häfen in der Tabelle cports
verzeichnet. Nun möchten wir allen Häfen, die auf Korsika liegen, die
potentiellen Verbindungsziele am Festland zuweisen (≈ alle Häfen, die
nicht auf Korsika liegen):
SELECT * FROM cports AS a JOIN cports AS b ON (a.region LIKE 'Corse' AND b.region NOT LIKE 'Corse');
Schnell merken wir, dass diese Auflistung nicht
zufriedenstellend sein kann, da noch nicht geklärt ist, welche dieser
potentiellen Verbindungen denn nun tatsächlich Fährbetrieb aufweisen.
Hierzu wird ein weiterer Join, mit der Tabelle cconnections,
benötigt:
SELECT * FROM cports AS a JOIN cports AS b ON (a.id NOT LIKE b.id AND a.region LIKE 'Corse' AND b.region NOT LIKE 'Corse') JOIN cconnections AS c ON (a.id = c.aid AND b.id = c.bid);
LEFT JOIN (LEFT OUTER JOIN)/ RIGHT JOIN (RIGHT OUTER JOIN)
Ausgegeben werden beim Left Join alle
Datensätze der linken Tabelle,
auch dann, wenn es seitens der gejointen
rechten Tabelle keine korrespondierenden Einträge gibt.
Korrespondierende Informationen der rechten Tabelle werden, sofern
vorhanden, den entsprechenden Einträgen angefügt.
Merke: Tabelle A LEFT JOIN Tabelle B gibt dasselbe
Ergebnis aus wie Tabelle B RIGHT JOIN Tabelle A
Wird bei der vorgenannten SQL-Abfrage der zweite JOIN zur Tabelle
cconnections zu einem LEFT JOIN, so werden damit auch alle
Häfen angezeigt, zwischen denen keine
Fährverbindung besteht:
SELECT * FROM cports AS a JOIN cports AS b ON (a.id NOT LIKE b.id AND a.region LIKE 'Corse' AND b.region NOT LIKE 'Corse') LEFT JOIN cconnections AS c ON (a.id = c.aid AND b.id = c.bid) WHERE c.aid IS NULL;
Um unsere eben erlernten Kenntnisse im Bereich
der verknüpften Abfrage von Tabellen zu intensivieren, sehen wir uns ein
weiteres Beispiel für INNER JOIN/LEFT JOIN an: Beispiel
Vorlesungsverzeichnis:
— "dozent" (persid, titel, name,
vorname, einrichtung)
— "kurs" (vlid, titel, beschreibung,
art, persid, belid)
— "belegung" (belid, gebäude, raum,
vlid)
-
INNER JOIN
~ Listen Sie alle Dozenten und die zugehörigen Lehrveranstaltungen auf unter Berücksichtigung des Titels und der Art der Veranstaltung sowie Name und Vorname, zusammengefasst (Name, Vorname):
SELECT kurs.titel, art, CONCAT(`name`, ',', `vorname`) FROM dozent INNER JOIN kurs ON dozent.persid = kurs.persid;
-
LEFT JOIN
~ Listen Sie alle Dozenten mit Lehrveranstaltung auf, aber auch diejenigen, die aktuell keine Lehrveranstaltung anbieten. Vorlesungen, denen noch keine Lehrperson zugeordnet wurde, sollen nicht angezeigt werden; unter Berücksichtigung oben genannter Parameter:
SELECT CONCAT(`name`, ',', `vorname`) FROM dozent LEFT JOIN kurs ON dozent.persid = kurs.persid WHERE kurs.persid IS NOT NULL;
~ Ordnen Sie nun noch alle Dozenten absteigend an, beginnend bei dem mit den meisten angebotenen Lehrveranstaltungen; unter Berücksichtigung oben genannter Parameter:
SELECT COUNT(kurs.persid) AS Anzahl, CONCAT(`name`, ',', `vorname`) FROM dozent LEFT JOIN kurs ON dozent.persid = kurs.persid GROUP BY name DESC;
-
INNER JOIN mit drei Tabellen
~ Joins können auch auf mehr als zwei Tabellen angewendet werden, wie Sie dem folgendem Beispiel entnehmen können. Dabei gilt stets: Bei der Verbindung von n Tabellen sind stets n-1 Join-Kriterien erforderlich. Listen Sie alle Dozenten (Name, Vorname) mit den zugehörigen Lehrveranstaltungen und den entsprechenden Vorlesungssälen auf:
SELECT dozent.name, dozent.vorname, kurs.titel, belegung.raum FROM dozent, kurs, belegung WHERE kurs.persid = dozent.persid AND kurs.belid = belegung.vlid;
(FULL) OUTER JOIN
Ausgegeben werden beim FULL OUTER JOIN alle
Datensätze der linken und rechten
Tabelle, eingegrenzt ggf. durch eine WHERE-Klausel. Es handelt
sich also um eine Kombination aus LEFT und RIGHT JOIN.
Datensätze, deren Verknüpfungsbedingungen übereinstimmen, werden in
einer Zeile ausgegeben. Wo dies nicht der Fall ist, wird in den Zellen
der Zeile (beider Tabellen) ein NULL-Wert
ausgegeben:
SELECT name FROM dozent FULL OUTER JOIN kurs ON dozent.persid = kurs.persid
Nun haben Sie sich mit den verschiedenen Arten
von Joins das Rüstzeug für einen vertieften Zugang zu Datenbanken
erarbeitet. Für einen praktischen Einstieg in die
Arbeit mit SQL-Datenbanken unter korpuslinguistischen
Aspekten sei auf das Beispiel "Grimmsche Märchen" auf DH-Lehre
verwiesen.
UNION
Neben Joins gibt es auch die Möglichkeit, zwei
Abfrageergebnisse untereinander zu kombinieren, sofern sie
beide eine identische Anzahl an Spalten aufweisen und
die hierfür ausgewählten Spalten den gleichen Datentyp
besitzen. Diese Art der Verbindung wird als UNION
bezeichnet und kann über verschiedene Tabellen, Datenbanken bis hin zu
Servern angewendet werden.
Bei einer UNION-Abfrage werden
alle Duplikate eliminiert (vergleichbar mit einer
SELECT-Abfrage mit DISTINCT-Ergänzung). Um auch die Duplikate zu
erhalten, muss das Statement UNION ALL verwendet
werden:
SELECT spalte1, spalte2 FROM tabelle1 UNION SELECT spalte 1, spalte 2 FROM tabelle2
Einfaches Beispiel zur
Veranschaulichung: Die Datenbank eines Forums wird unterteilt eine
Tabelle für die Fragen und eine Tabelle für die darauf bezogenen
Antworten. Nun gibt es Nutzer, die Fragen und/oder Antworten verfasst
haben. Um alle Nutzer aufzulisten, die bisher im Forum entweder durch
Fragen oder Antworten (oder beides) aktiv geworden sind, kann man den
UNION-Befehl einsetzen:
SELECT nutzer_id FROM fragen UNION SELECT nutzer_id FROM antworten
Tipp: Sollten die Anzahl Ihrer Spalten
nicht übereinstimmen, können Sie sich mit NULL (oder einem beliebigen
anderen Wert) behelfen:
SELECT spalte1, spalte2, spalte3 FROM tabelle1 UNION SELECT spalte 1, spalte 2, NULL FROM tabelle2
Anmerkungen
- Vgl. dev.mysql.com/doc/refman/5.7/en/↩︎
- Vgl. hierfür das Kapitel zu String-Funktionen der MySQL-Dokumentation.↩︎
- Vgl. den entsprechenden Abschnitt in DH-Lehre.↩︎
- Zur besseren Illustration des Problems sei folgende Metapher verwandt: Stellen Sie sich vor, es gibt zwei Personengruppen, eine rot, die andere blau gekleidet. Sie gruppieren beide Farben, sodass sie nun zwei Personenreihen haben. Jedoch ist nur die vorderste, größte Person zu sehen. Um alle Personen sehen zu können, muss ein weiterer Befehl angewendet werden.↩︎
- Vgl. hierfür das entsprechende Kapitel in [vgl. hierzu: https://www.dh-lehre.gwi.uni-muenchen.de/?p=33389 dh-lehre].↩︎
Datenbank-Praxis für Fortgeschrittene
Einsatz von Indizes
Indizes sind vergleichbar mit Registern in Büchern;
wird nach einem Begriff gesucht, so findet man mit Hilfe eines Registers
bzw. Index recht schnell die jeweiligen Vorkommen des Begriffs.
Bei MySQL gibt es verschiedene Möglichkeiten
der Indizierung (die wichtigsten 3):
PRIMARY KEY: Der Primary Key dient zur eindeutigen Identifizierung eines Datensatzes und kommt daher meist in der ID-Spalte zum Einsatz.INDEX KEY: Der Index Key erscheint sinnvoll, wenn man Tabellenfelder kürzeren Inhalts als Ganzes von MySQL erfassen und verwalten lassen möchte.FULLTEXT KEY: Im Gegensatz zum Index Key erfasst der Fulltext Key jedes Einzelwort eines Tabellenfeldes (Bedingung: FeldtypCHAR,VARCHARoderTEXT); um relevante Ergebnisse zu erzielen, sollten die Einträge in den Tabellenfeldern größere Mengen an Wörtern umfassen. Es empfiehlt sich, den Index erst nach dem Befüllen einer Tabelle mit Inhalten zu setzen.
Berechnungen in MySQL
Neben der Abfrage von Daten und Veränderungen am Datenbestand ist es
auch möglich, in MySQL Rechenoperationen auszuführen.
Zur Verfügung stehen die üblichen Grundrechenarten (+, -, /, *). Es sind
aber auch komplexere mathematische Funktionen möglich (z.B. Cosinus,
Sinus), oder beispielsweise auch die Berechnung der Distanz zwischen
zwei GPS-Koordinaten.
Einige Beispiele:
| Rechenoperation | Beschreibung |
|---|---|
UPDATE tabellenname SET anzahl = anzahl + 3 WHERE id = 15;
|
Beim Eintrag mit der ID = 15 wird der Wert in der Spalte anzahl um 3 addiert. |
UPDATE tabellenname SET anzahl = anzahl * anzahl2 WHERE id = 15;
|
Beim Eintrag mit der ID = 15 wird der Wert in der Spalte anzahl mit dem Wert aus der Spalte anzahl2 multipliziert. |
SELECT 1 / 3; |
Einfache Division. |
SELECT 1 + 3; |
Einfache Addition. |
SELECT ROUND(1/3, 2); |
Das Ergebnis der Division wird durch die eingebundene Funktion auf zwei Nachkommastellen gerundet. |
SELECT AVG(anzahl) AS Durchschnitt FROM tabellenname;
|
Ermittlung eines Durchschnittswertes in aller in der Spalte anzahl befindlichen Werte. |
Gewichtete Abfragen
Der sinnvolle Einsatz von gewichteten Abfragen ist in verschiedenen
Anwendungsszenarien denkbar, beispielsweise um Wahrscheinlichkeiten zu
ermitteln, aber auch, um Volltextsuchen zu optimieren. Letzteres möchten
wir uns in diesem Abschnitt exemplarisch näher ansehen:
>
Mit Hilfe des Fulltext-Index wird in der damit versehenen
Tabellenspalte eine Volltextsuche ermöglicht. Diese kann sinnvollerweise
in ein Skript eingebunden werden. Zum Einsatz kommen dabei die
Funktionen MATCH() und AGAINST()
MATCH(): alle Spalten, die in die Suche eingebunden werden sollen, werden in dieser Funktion, kommasepariert angegeben.AGAINST(): enthält den String, nach dem gesucht werden soll.
Es existieren verschiedene Suchtypen, mit denen die Art der Suche definiert wird - u.a.:
IN NATURAL LANGUAGE MODE: Der gesuchte String wird bei diesem Suchtyp als natürliche Sprache angesehen. Vorteilhaft erweist sich, dass sämtliche Wörter, die in mehr als 50% der passenden Datensätze vorkommen, aus dem Matching-Raster fallen, da sie als zu gewöhnlich erkannt werden.IN BOOLEAN MODE: Der gesuchte String kann bei diesem Suchtyp bestimmte Operatoren enthalten, die definieren, ob ein Wort enthalten sein muss (+) oder ein Wort nicht enthalten sein darf (-); außerdem kann eine Gewichtung der einzelnen Worte erfolgen.
Beispiele:
SELECT * FROM historiker
WHERE MATCH (name, ort)
AGAINST ('Max Mannheimer' IN NATURAL LANGUAGE MODE);
Mit dieser Abfrage würde man erhalten:
— "Max
Mannheimer"
— alle Personen die "Max/imilian" mit Vornamen
heißen
— alle Personen, die an der Universität "Mannheim"
unterrichten
SELECT * FROM historiker
WHERE MATCH (name, ort)
AGAINST ('Max Mannheimer' IN BOOLEAN MODE);
Die Änderung des Suchtyps würde in diesem Fall noch zu
keiner Veränderung am Suchergebnis führen. Hierzu müssen noch
Operatoren zum Einsatz kommen, die der Boolean Mode zulässt:
SELECT * FROM historiker
WHERE MATCH (name, ort)
AGAINST ('+Max +Mannheimer', '-Mannheim' IN BOOLEAN MODE);
Mit dieser Abfrage würde man nun nur noch einen
Treffer (Max Mannheimer) erhalten.
Gewichtung einer Suchanfrage:
SELECT `tabellenspalte` FROM `tabellenname` WHERE
(
3 * (MATCH(`spalte1`) AGAINST ('suchbegriff' IN BOOLEAN MODE))
+
1.5 * (MATCH(`spalte2`) AGAINST ('suchbegriff' IN BOOLEAN MODE))
)
AS relevance HAVING relevance > 0.5 ORDER BY relevance;
In diesem Fall ist Spalte 1 am
wichtigsten für die Suche, gefolgt von Spalte
2.
Unterabfragen (Subqueries) und "IN"-Operator
- In einer SELECT-Anfrage kann als sogenannte Unterabfrage (Subquery) ein weiteres SELECT-Statement eingebunden werden. Die Unterabfrage wird durch Klammerung definiert und muss einen Korrelationsnamen erhalten. Unterabfragen sind u.a. dann sinnvoll, wenn es darum geht, Join-Abfragen zu beschleunigen.
Beispiel für eine einfache Unterabfrage:
~ Ermitteln Sie alle Historiker (Vorname, Name, Gehalt) aus der
Tabelle Historiker, deren Gehalt höher ist als das Durschnittsgehalt
aller Personen in dieser Tabelle, sortiert nach der Höhe des Gehalts in
absteigender Reihenfolge:
SELECT vorname, name, gehalt FROM Historiker
WHERE gehalt > (SELECT AVG(gehalt) FROM Historiker)
ORDER BY gehalt DESC;
- Unterabfragen können verwendet werden, um in einer WHERE-Klausel eine Werteliste mit dem logischen Operator "IN" zu erzeugen. Der IN-Operator wird verwendet, um mehrere OR-Abfragen zu bündeln, d.h. um die Abfrage in einer Spalte auf mehr als einen Abfragewert zu erweitern.
Beispiel für eine einfache Abfrage mit
IN-Operator:
SELECT vorname, name, land FROM Historiker
WHERE land IN ("Deutschland", "Frankreich", "Schweiz");
Anstelle:
SELECT vorname, name, land FROM Historiker
WHERE land = "Deutschland" OR land = "Frankreich" OR land = "Schweiz");
Einsatz von Views ("gespeicherten Abfragen")
Es besteht in MySQL die Möglichkeit, sogenannte "Views" oder "Sichten" zu erstellen. Dabei handelt es sich um eine Art virtuelle Tabelle, die auf dem Ergebnis eines SQL-Statements basiert:
- Ein View besteht aus Spalten und Zeilen wie eine 'echte' Tabelle. Die Tabellenfelder sind Felder einer oder mehrerer Tabellen aus einer Datenbank.
- Views sind in erster Linie dafür gedacht, Nutzern einen beschränkten
Zugang zu den Daten zu gewähren. Für die Veränderung des Datenbestandes
(
INSERT,UPDATE,DELETE) sind Views nicht vorgesehen. - Views erscheinen daher sinnvoll, wenn den Anwendern eines Webinterface nur eine begrenzte Anzahl an Spalten oder Zeilen zur Verfügung gestellt werden sollen. Die Anzahl der Spalten wird durch die Auswahl der Spalten in der SELECT-Anfrage geregelt, die Anzahl der Zeilen durch die WHERE-Klausel.
- In einem View können Abfragen aller Art durchgeführt werden.
- Views sind immer so aktuell, wie die dahinter liegenden Tabellen. Die Database Engine ruft das, dem View zugrunde liegende SQL-Statement stets neu ab, wenn ein Benutzer eine Anfrage stellt, und aktualisiert damit sukzessive den im View hinterlegten Datenbestand.
- Views lassen sich gut in der Programmierung einbinden; ändert sich beispielsweise ein Tabellenname, so muss dieser nur einmal in der Datenbank korrigiert werden. Die in ein Skript eingebundenen Views bleiben davon unberührt. Diese Vermeidung von Redundanzen (Stichwort: Normalisierung) vermeidet eine unnötige Suche und daraus resultierende Fehleranfälligkeit.
- Nachteil von Views: Vorhandene Spalten-Indizes (wie der Primary Key) gehen bei der Erstellung verloren. Je nach Datenmenge kann dies zu Lasten der Performance gehen.
Anlegen eines VIEWS (Grundgerüst):
CREATE VIEW viewname AS
SELECT ...
FROM ...
WHERE ...;
(WHERE-Klausel optional)
Update eines VIEWS (Grundgerüst):
CREATE OR REPLACE VIEW viewname AS
SELECT ...
FROM ...
WHERE ...;
(WHERE-Klausel optional)
Ein View kann - wie eine Tabelle -
gelöscht werden: DROP VIEW viewname;